算分是Apache Lucene 查询处理过程中的一个重要环节。算分是指针给定查询计算某个文档的分值属性的过程。ES会对每个匹配查询条件的结构进行算分。算分的本质是排序,也就是把最符合用于预期的结果排在前面。在ES5之前,默认的相关性算分使用TF-IDF算法,而最新的算法使用BM25。
词频(TF)
词频是检查词在一篇文档里出现的频率,也就是检查词出现的次数 / 文档的总字数。对于度量一个语句的TF就可以简单的认为组成其词项的TF相加,如下所示:
TF(我的祖国) = TF(我) + TF(的) + TF(祖国)
停用词(stop word)
停用词表示在文档中出现的频率较高,但是对搜索评分几乎没有用处,因此不考虑其TF,如上面的"的"字。
逆文档频率(IDF)
下面看一下逆文档频率的公式:
IDF = log(全部文档数 / 检索词出现过的文档数)TF-IDF
TF-IDF 本质上就是TF 与 IDF 的加权求和:
TF-IDF = TF(我)*IDF(我) + TF(的)*IDF(的) + TF(祖国)*IDF(祖国)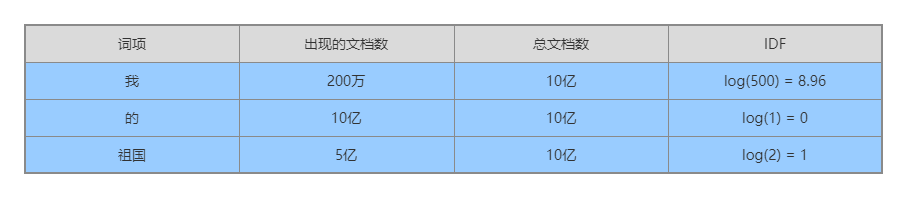
TF-IDF 被认为是信息检索领域最重要的发明。除了在信息检索领域,在文献分类和其他领域都有着广泛的应用。
BM25
从ES5开始,默认的评分算法改为BM25。和经典的TF-IDF相比,当TF无限增加时,BM25会趋向于一个稳定值。
Demo
下面我们看一下下面的例子。
PUT new_movie/_bulk
{"index":{"_id":1}}
{"name":"我的祖国", "online_date":"2020-10-01"}
{"index":{"_id":2}}
{"name":"我和我的祖国", "online_date":"2020-10-01"}
{"index":{"_id":3}}
{"name":"我的家乡", "online_date":"2020-10-01"}当我们使用如下语句查询,并且将explain 打开,此时可以看到算分的详细结果。搜索结果中,"我和我的祖国"这部电影的算分最高。
POST /new_movie/_search
{
"explain": true,
"query": {
"match": {
"name": "我"
}
}
}Boosting 设置



