查询和过滤的区别
查询(Query):用于检查内容与条件是否匹配,并且计算_score 元字段表示匹配度。查询的结构中以 query 参数开始来执行内容查询。
过滤(Filter):不计算匹配得分,只是简单的决定文档是否匹配。内容过滤主要用于过滤结构化数据。如:时间是否在2020-2021,Status 是否是 SUCCESS等。
Term查询
Term(词项)是表达语义的最小单位,Term 级别的查询包括:Term 查询、Range 查询、Exists 查询、Prefix 查询、Wildcard 查询。
在ES中,对Term查询不做分词处理。词项会作为一个整体,在倒排索引中查找准确的匹配项;并且使用相关度算分公式为每个匹配的文档进行相关度算分。可以通过 Constant Score,将查询转换为一个Filter,避免算分,提高性能。
下面我们看一下Term 查询的Demo,首先准备一下数据:
POST /cars/_bulk
{ "index": { "_id": 1 }}
{ "carId" : "2020-SH-PD-001","name":"Bluck","address":"上海浦东" }
{ "index": { "_id": 2 }}
{ "carId" : "2019-BJ-CY-109","name":"Benz","address":"北京朝阳" }
{ "index": { "_id": 3 }}
{ "carId" : "2020-NJ-QX-001","name":"BMW","address":"南京栖霞" }
当我们使用下面的 Term 查询时,会发现查不到数据。原因是在文档写入时,ES 会默认将倒排索引中将其转为小写,因此这里转为小写时就可以查出数据了。
POST /cars/_search
{
"query": {
"term": {
"name": {
// Bluck 为大写时查不到数据
//"value": "Bluck"
"value": "bluck"
}
}
}
}当我们使用 Term 对 cardId进行查询时,当使用 "2020-SH-PD-001" 进行查询时,会发现查询不到数据。原因是当文档写入ES时,会将cardId 进行分词为 2020 sh pd 001,然后写入倒排索引。因此我们需要使用上面4个词项进行 Term搜索才可以查出结果。
POST /cars/_search
{
"query": {
"term": {
"carId": {
//"value": "2020-SH-PD-001" // 查询不出结果
//"value": "sh"
"value": "2020"
//"value": "2020-sh-pd-001" // 查询不出结果
}
}
}
}那么我们如何才可以精确匹配 cardId呢?我们可以通过 cardId.keyword 关键字进行查询,如下所示。
POST /cars/_search
{
"query": {
"term": {
"carId.keyword": {
"value": "2020-SH-PD-001"
}
}
}
}查询类别
叶查询:在特定的字段上查找特定的值。如Match查询、Term查询、Range 查询等。
复合查询:包含其他叶查询或复合查询,以合理的方式结合多条查询(Boolean查询、dis_max查询),或者改变查询行为(not或者constant_score查询)。
下面我们看一个使用 constant_score 复合查询,将Query 转为 Filter 的例子。
POST /cars/_search
{
"explain": true,
"query": {
"constant_score": {
"filter": {
"term": {
"carId.keyword": "2020-SH-PD-001"
}
}
}
}
}全文查询
在讲全文查询之前,需要先了解一下分词。查询字符串首先会匹配到一个分词器,然后生成一个可查询的词项列表。查询会对每个词项进行底层的查询,然后再将其合并返回,并且会对每个文档生成一个算分。如搜索词为"北京",其查询过程大致如下。
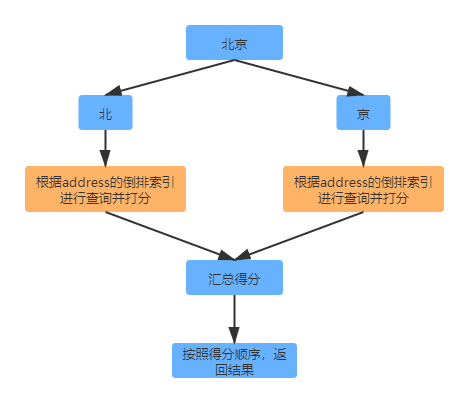
Match 查询
因为"北京"会被分词为 "北"和"京",所以下面的搜索会查询出2条结果,也就是 "北京"和"南京"都会被检索出来。但是"北京"的算分会比较高,排在前面。
POST /cars/_search
{
"query":{
"match": {
"address":{
"query": "北京"
}
}
}
}当我们对上面的查询条件增加 operator 参数时,意思也就是 address 字段中必须包含 "北"和"京",此时结果中只包含了1条结果。
POST /cars/_search
{
"query": {
"match": {
"address": {
"query": "北京",
"operator": "and"
}
}
}
}当我们把 operator 参数替换为 "minimum_should_match" 时,意思也就是分词项最小匹配2个,此时也只返回结果包含"北京"的文档了。
POST /cars/_search
{
"query": {
"match": {
"address": {
"query": "北京",
"minimum_should_match": 2
}
}
}
}Match Phase 查询
当使用Match Phase 查询时,slop 参数的意思是:查询的词项中间最多可以有1个其他字符,因此可以检索出 "北京"的文档。
POST /cars/_search
{
"query": {
"match_phrase": {
"address": {
"query": "北朝",
"slop": 1
}
}
}
}参考:《ElasticSearch技术解析与实战》、《极客时间:ElasticSearch核心技术与实战》



