从本文开始,我们会进入dubbo网络通信层的设计分析。本篇主要讲解一下Dubbo的协议以及对应的编解码器。
Dubbo协议
Dubbo协议的设计参考了TCP/IP协议,其中包含了协议头和协议体两个部分。采用了定长协议头+变长协议体(payload),16个字节的报文头包含了魔数(0xdabb)和请求响应标志、心跳、序列化标志等。其具体结构如下所示:

- Magic - Magic High & Magic Low (16 bits)
标识协议版本号,Dubbo 协议:0xdabb
- Req/Res (1 bit)
标识是请求或响应。请求: 1; 响应: 0。
- 2 Way (1 bit)
仅在 Req/Res 为1(请求)时才有用,标记是否期望从服务器返回值。如果需要来自服务器的返回值,则设置为1。
- Event (1 bit)
标识是否是事件消息,例如,心跳事件。如果这是一个事件,则设置为1。
- Serialization ID (5 bit)
标识序列化类型:比如 fastjson 的值为6。
- Status (8 bits)
仅在 Req/Res 为0(响应)时有用,用于标识响应的状态。
20 - OK
30 - CLIENT_TIMEOUT
31 - SERVER_TIMEOUT
40 - BAD_REQUEST
50 - BAD_RESPONSE
60 - SERVICE_NOT_FOUND
70 - SERVICE_ERROR
80 - SERVER_ERROR
90 - CLIENT_ERROR
100 - SERVER_THREADPOOL_EXHAUSTED_ERROR
- Request ID (64 bits)
标识唯一请求。类型为long。
- Data Length (32 bits)
序列化后的内容长度(可变部分),按字节计数。int类型。
- Variable Part
被特定的序列化类型(由序列化 ID 标识)序列化后,每个部分都是一个 byte [] 或者 byte
⇒ 如果是请求包 ( Req/Res = 1),则每个部分依次为:
Dubbo version
Service name
Service version
Method name
Method parameter types
Method arguments
Attachments
⇒ 如果是响应包(Req/Res = 0),则每个部分依次为:
返回值类型(byte),标识从服务器端返回的值类型:
返回空值:RESPONSE_NULL_VALUE 2
正常响应值: RESPONSE_VALUE 1
异常:RESPONSE_WITH_EXCEPTION 0
返回值:从服务端返回的响应bytes
Dubbo编解码器
对于Dubbo的编解码,我们先看下2.0.7版本是如何实现的。如下图所示:
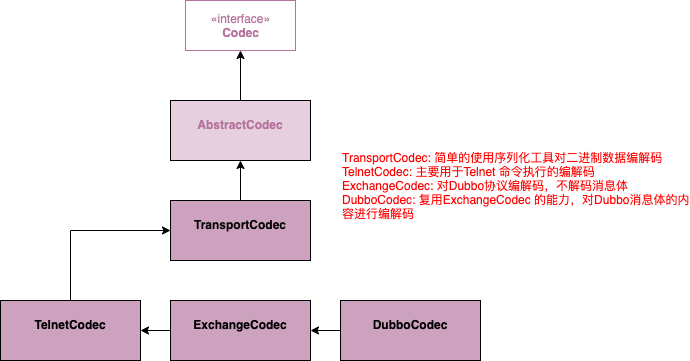
从上面类图关系可以看出,Dubbo编解码的核心类文件就6个。其中我们首先看下顶层的2个抽象,Codec和AbstractCodec。
Codec
@Extension
public interface Codec {
/**
* 需要更多的输入标志
*
* @see #decode(Channel, InputStream)
*/
Object NEED_MORE_INPUT = new Object();
/**
* 消息编码
*
* @param channel channel.
* @param output output stream.
* @param message message.
*/
@Adaptive({Constants.CODEC_KEY})
void encode(Channel channel, OutputStream output, Object message) throws IOException;
/**
* 消息解码
*
* @see #NEED_MORE_INPUT
* @param channel channel.
* @param input input stream.
* @return message or <code>NEED_MORE_INPUT</code> poison.
*/
@Adaptive({Constants.CODEC_KEY})
Object decode(Channel channel, InputStream input) throws IOException;
}
从上面的Codec顶层接口可以看出,只有编解码的两个方法。但是细心的读者可以看到,通常编解码只需要Object 和 二进制数据之间的相互转化,为什么上面的接口入参还有Channel 这个类型的参数?原因是因为URL是始终围绕着Dubbo的一个东西,而Channel 里面可以获取到 URL。通过URL可以获取到序列化类型,寻找SPI实现等。
我们可以看到还有一个常量NEED_MORE_INPUT,这个是给TelnetCodec定义使用的。意思是当解码输入的二进制时,当不满足命令的结束标志时,会通过这个对象提示调用方需要继续数据相关命令字符。
AbstractCodec
public abstract class AbstractCodec implements Codec {
// 获取序列化类型
protected Serialization getSerialization(Channel channel) {
String serializationKey = channel.getUrl().getParameter(Constants.SERIALIZATION_KEY, Constants.DEFAULT_REMOTING_SERIALIZATION);
return ExtensionLoader.getExtensionLoader(Serialization.class).getExtension(serializationKey);
}
// 检查消息体大小
protected void checkPayload(Channel channel, long size) throws IOException {
int payload = Constants.DEFAULT_PAYLOAD;
if (channel != null && channel.getUrl() != null) {
payload = channel.getUrl().getPositiveIntParameter(Constants.PAYLOAD_KEY, Constants.DEFAULT_PAYLOAD);
}
if (size > payload) {
throw new IOException("Data length too large: " + size + ", max payload: " + payload + ", channel: " + channel);
}
}
}从上面的AbstractCodec可以看出,其并没有什么抽象的模板方法,而是两个工具方法。其中一个是获取序列化类型的,另外一个是检查消息体是否过载的。
TransportCodec
@Extension("transport")
public class TransportCodec extends AbstractCodec {
@Override
public void encode(Channel channel, OutputStream output, Object message) throws IOException {
ObjectOutput objectOutput = getSerialization(channel).serialize(channel.getUrl(), output);
encodeData(channel, objectOutput, message);
objectOutput.flushBuffer();
}
@Override
public Object decode(Channel channel, InputStream input) throws IOException {
return decodeData(channel, getSerialization(channel).deserialize(channel.getUrl(), input));
}
protected void encodeData(Channel channel, ObjectOutput output, Object message) throws IOException {
encodeData(output, message);
}
protected Object decodeData(Channel channel, ObjectInput input) throws IOException {
return decodeData(input);
}
protected void encodeData(ObjectOutput output, Object message) throws IOException {
output.writeObject(message);
}
protected Object decodeData(ObjectInput input) throws IOException {
try {
return input.readObject();
} catch (ClassNotFoundException e) {
throw new IOException("ClassNotFoundException: " + StringUtils.toString(e));
}
}
}TransferCode这个类的编解码也相对比较简单,也就是将Object和二进制之间进行转换,其实并没有对Dubbo协议本身进行编解码,也即是直接使用了序列化类进行编解码。
TelnetCodec
private static final String HISTORY_LIST_KEY = "telnet.history.list";
private static final String HISTORY_INDEX_KEY = "telnet.history.index";
private static final byte[] UP = new byte[]{27, 91, 65};
private static final byte[] DOWN = new byte[]{27, 91, 66};
private static final List<?> ENTER = Arrays.asList(new Object[]{new byte[]{'\r', '\n'} /* Windows Enter */, new byte[]{'\n'} /* Linux Enter */});
private static final List<?> EXIT = Arrays.asList(new Object[]{new byte[]{3} /* Windows Ctrl+C */, new byte[]{-1, -12, -1, -3, 6} /* Linux Ctrl+C */, new byte[]{-1, -19, -1, -3, 6} /* Linux Pause */});
@Override
public void encode(Channel channel, OutputStream output, Object message) throws IOException {
if (message instanceof String) {
if (isClientSide(channel)) {
message = message + "\r\n";
}
byte[] msgData = ((String) message).getBytes(getCharset(channel).name());
output.write(msgData);
output.flush();
} else {
super.encode(channel, output, message);
}
}
@Override
public Object decode(Channel channel, InputStream is) throws IOException {
int readable = is.available();
byte[] message = new byte[readable];
is.read(message);
return decode(channel, is, readable, message);
}TelnetCodec是针对于命令行输入的编解码,主要处理命令客户端相关的编解码。上面的代码笔者只是摘要了一部分,从成员变量可以看出,会有一些键盘上的回车/向上翻页/向下翻页等键盘符的静态变量。另外编码是对String的编码,然后其他的类型会调用TransportCodec的编码。对于解码而言,则是会根据用户在客户端命令行的输入,决定是否解码完成。如:命令结束符回车,表示本次解码可以完成,然后再由上层判断解码出来的字符是否符合命令规范。
ExchangeCodec & DubboCodec
// header length.
protected static final int HEADER_LENGTH = 16;
// magic header.
protected static final short MAGIC = (short) 0xdabb;
protected static final byte MAGIC_HIGH = (byte) Bytes.short2bytes(MAGIC)[0];
protected static final byte MAGIC_LOW = (byte) Bytes.short2bytes(MAGIC)[1];
// message flag.
protected static final byte FLAG_REQUEST = (byte) 0x80;
protected static final byte FLAG_TWOWAY = (byte) 0x40;
protected static final byte FLAG_HEARTBEAT = (byte) 0x20;
protected static final int SERIALIZATION_MASK = 0x1f;
private static Map<Byte, Serialization> ID_SERIALIZATION_MAP = new HashMap<Byte, Serialization>();
static {
Set<String> supportedExtensions = ExtensionLoader.getExtensionLoader(Serialization.class).getSupportedExtensions();
for (String name : supportedExtensions) {
Serialization serialization = ExtensionLoader.getExtensionLoader(Serialization.class).getExtension(name);
byte idByte = serialization.getContentTypeId();
if (ID_SERIALIZATION_MAP.containsKey(idByte)) {
logger.error("Serialization extension " + serialization.getClass().getName()
+ " has duplicate id to Serialization extension "
+ ID_SERIALIZATION_MAP.get(idByte).getClass().getName()
+ ", ignore this Serialization extension");
continue;
}
ID_SERIALIZATION_MAP.put(idByte, serialization);
}
}
public Short getMagicCode() {
return MAGIC;
}
@Override
public void encode(Channel channel, OutputStream os, Object msg) throws IOException {
if (msg instanceof Request) {
encodeRequest(channel, os, (Request) msg);
} else if (msg instanceof Response) {
encodeResponse(channel, os, (Response) msg);
} else {
super.encode(channel, os, msg);
}
}
@Override
public Object decode(Channel channel, InputStream is) throws IOException {
int readable = is.available();
byte[] header = new byte[Math.min(readable, HEADER_LENGTH)];
is.read(header);
return decode(channel, is, readable, header);
}对于ExchangeCodec而言,其本身对Dubbo协议头的解析,而对于协议体的解析是放到DubboCodec中去处理的,也就是交换层只关心协议头。上面的代码只是一部分,从成员变量可以看出,它包含了Dubbo协议头的相关信息。下方的encode()和decode() 方法,也是直接重写了父类的方法。
对于编码而言,只处理了Request和Responsel2种对象的编码,其余的对象调用的是父类的编码方法。(TelnetCodec只处理String类型的编码,其余的交给了TransportCodec处理)下面我们先看下对请求的编码:
protected void encodeRequest(Channel channel, OutputStream os, Request req) throws IOException {
Serialization serialization = getSerialization(channel);
// header.
byte[] header = new byte[HEADER_LENGTH];
// set magic number.
Bytes.short2bytes(MAGIC, header);
// set request and serialization flag.
header[2] = (byte) (FLAG_REQUEST | serialization.getContentTypeId());
if (req.isTwoWay()) {
header[2] |= FLAG_TWOWAY;
}
if (req.isHeartbeat()) {
header[2] |= FLAG_HEARTBEAT;
}
// set request id.
Bytes.long2bytes(req.getId(), header, 4);
// encode request data.
UnsafeByteArrayOutputStream bos = new UnsafeByteArrayOutputStream(1024);
ObjectOutput out = serialization.serialize(channel.getUrl(), bos);
if (req.isHeartbeat()) {
encodeHeartbeatData(channel, out, req.getData());
} else {
encodeRequestData(channel, out, req.getData());
}
out.flushBuffer();
bos.flush();
bos.close();
byte[] data = bos.toByteArray();
Bytes.int2bytes(data.length, header, 12);
// write
os.write(header); // write header.
os.write(data); // write data.
}上面的代码也比较简单,就是按照Dubbo协议头去拼装二进制数据。不过这里有一点需要注意的是,如果是Dubbo协议,encodeRequestData() 方法会被DubboCodec重写,此时会对请求体进一步的进行编码。其代码实现在DubboCodec中,如下所示:
@Override
protected void encodeRequestData(Channel channel, ObjectOutput out, Object data) throws IOException {
RpcInvocation inv = (RpcInvocation) data;
out.writeUTF(inv.getAttachment(Constants.DUBBO_VERSION_KEY, DUBBO_VERSION));
out.writeUTF(inv.getAttachment(Constants.PATH_KEY));
out.writeUTF(inv.getAttachment(Constants.VERSION_KEY));
out.writeUTF(inv.getMethodName());
out.writeUTF(ReflectUtils.getDesc(inv.getParameterTypes()));
Object[] args = inv.getArguments();
if (args != null) {
for (int i = 0; i < args.length; i++) {
out.writeObject(encodeInvocationArgument(channel, inv, i));
}
}
out.writeObject(inv.getAttachments());
}对于上述的代码,也相对比较简单,就是开篇说到的Dubbo协议的payload组装。同理对于Response的编码也是类似的,这里就不再赘述。
对于ExchangeCodec的解码,其也是只解码了消息头,解码消息体(payload)是在DubboCodec中实现的。我们首先看下ExchangeCodec对消息头的解码过程:
@Override
protected Object decode(Channel channel, InputStream is, int readable, byte[] header) throws IOException {
// check magic number.
if (readable > 0 && header[0] != MAGIC_HIGH || readable > 1 && header[1] != MAGIC_LOW) {
int length = header.length;
if (header.length < readable) {
header = Bytes.copyOf(header, readable);
is.read(header, length, readable - length);
}
for (int i = 1; i < header.length - 1; i++) {
if (header[i] == MAGIC_HIGH && header[i + 1] == MAGIC_LOW) {
UnsafeByteArrayInputStream bis = ((UnsafeByteArrayInputStream) is);
bis.position(bis.position() - header.length + i);
header = Bytes.copyOf(header, i);
break;
}
}
return super.decode(channel, is, readable, header);
}
// check length.
if (readable < HEADER_LENGTH) {
return NEED_MORE_INPUT;
}
// get data length.
int len = Bytes.bytes2int(header, 12);
checkPayload(channel, len);
int tt = len + HEADER_LENGTH;
if (readable < tt) {
return NEED_MORE_INPUT;
}
// limit input stream.
if (readable != tt) {
is = StreamUtils.limitedInputStream(is, len);
}
byte flag = header[2], proto = (byte) (flag & SERIALIZATION_MASK);
Serialization s = getSerializationById(proto);
if (s == null) {
s = getSerialization(channel);
}
ObjectInput in = s.deserialize(channel.getUrl(), is);
// get request id.
long id = Bytes.bytes2long(header, 4);
if ((flag & FLAG_REQUEST) == 0) {
// decode response.
Response res = new Response(id);
res.setHeartbeat((flag & FLAG_HEARTBEAT) != 0);
// get status.
byte status = header[3];
res.setStatus(status);
if (status == Response.OK) {
try {
Object data;
if (res.isHeartbeat()) {
data = decodeHeartbeatData(channel, in);
} else {
data = decodeResponseData(channel, in);
}
res.setResult(data);
} catch (Throwable t) {
res.setStatus(Response.CLIENT_ERROR);
res.setErrorMessage(StringUtils.toString(t));
}
} else {
res.setErrorMessage(in.readUTF());
}
return res;
} else {
// decode request.
Request req = new Request(id);
req.setVersion("2.0.0");
req.setTwoWay((flag & FLAG_TWOWAY) != 0);
req.setHeartbeat((flag & FLAG_HEARTBEAT) != 0);
try {
Object data;
if (req.isHeartbeat()) {
data = decodeHeartbeatData(channel, in);
} else {
data = decodeRequestData(channel, in);
}
req.setData(data);
} catch (Throwable t) {
// bad request
req.setBroken(true);
req.setData(t);
}
return req;
}
}从从上面代码可以看出,解码也是按照Request/Response的维度进行的。此时当消息头解析完成后,如果是响应消息,会调用DubboCodec的decodeResponseData()方法进入消息体的解码过程。
@Override
protected Object decodeResponseData(Channel channel, ObjectInput in) throws IOException {
RpcResult result = new RpcResult();
byte flag = in.readByte();
switch (flag) {
case RESPONSE_NULL_VALUE:
break;
case RESPONSE_VALUE:
try {
result.setResult(in.readObject());
} catch (ClassNotFoundException e) {
throw new IOException(StringUtils.toString("Read response data failed.", e));
}
break;
case RESPONSE_WITH_EXCEPTION:
try {
Object obj = in.readObject();
if (obj instanceof Throwable == false) {
throw new IOException("Response data error, expect Throwable, but get " + obj);
}
result.setException((Throwable) obj);
} catch (ClassNotFoundException e) {
throw new IOException(StringUtils.toString("Read response data failed.", e));
}
break;
default:
throw new IOException("Unknown result flag, expect '0' '1' '2', get " + flag);
}
return result;
}参考:《深入理解Apache Dubbo 与实战》、Dubbo 2.6.0 源代码、Dubbo 2.0.7 源代码



