索引是具有相同结构的文档集合。在ElasticSearch中大部分操作都是基于索引来完成的。将数据存储到ElasticSearch中的过程,叫做索引(动词)。一个ES集群中可以包含多个索引,每个索引可以包含多个类型。这些不同的类型存储着多个文档,每个文档会包含多个属性。
索引(名词):如上一篇文章所示,一个索引可以类比为关系型数据库的一张表。
索引(动词):索引一个文档,就是将一个文档存储到ES当中,也就是将文档存储到一个索引(名词)中。这非常类似于SQL中的Insert 语句,不过有所区别的是,索引一个文档,如果文档已存在则更新,如果不存在则创建。
倒排索引
倒排索引是搜索引擎的核心技术之一,正是因为有倒排索引,搜索引擎才能有效率的进行查询、删除等操作。
我们说的倒排索引,我们可以对比正排索引。比如图书的目录结构就是一种正排索引,通过文章标题找到对应的页码。对于倒排索引,我们通过下面的文档转换看一下。

倒排索引的转换,是通过索引关键字的维度进行的。比如下面通过的关键字维度进行索引:
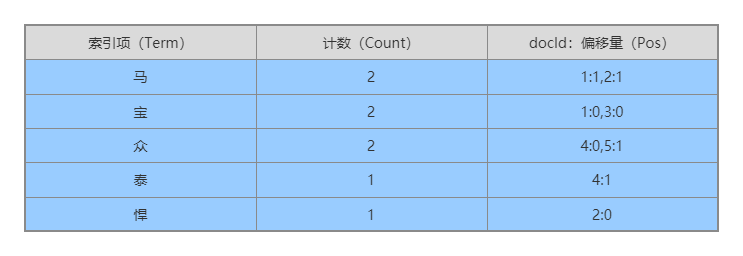
倒排索引包含两部分:单词词项、倒排列表。
单词词项:记录所有文档的单词,记录单词到倒排列表的关联关系。因为单词的数量比较大,通常会以B+树或者Hash链表的方式实现,以满足高效的查询与删除操作。
倒排列表:记录了单词对应的文档集合,由倒排索引项组成。倒排索引项包含:文档ID、词频(单词出现的频率)、单词在对应文档中的偏移量。
索引操作
创建文档(Create)
ES支持自动生成ID或者手动指定ID创建文档。
自动生成ID
POST /blogs/_doc
{
"title":"ElasticSearch索引",
"category":"ElasticSearch",
"tags":[
"ElasticSearch",
"原理"
]
}
手动指定ID
PUT /blogs/_create/1
{
"title":"ElasticSearch架构",
"category":"ElasticSearch",
"tags":[
"ElasticSearch",
"架构"
]
}当手动指定ID索引文档时,如果第二次执行上面创建文档数据,此时会返回如下结果:
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[1]: version conflict, document already exists (current version [1])",
"index_uuid": "sQ_DCF0ORye3cKy6yfdCPA",
"shard": "0",
"index": "blogs"
}
],
"type": "version_conflict_engine_exception",
"reason": "[1]: version conflict, document already exists (current version [1])",
"index_uuid": "sQ_DCF0ORye3cKy6yfdCPA",
"shard": "0",
"index": "blogs"
},
"status": 409
}获取文档(Get)
GET /blogs/_doc/1返回文档结果:
{
"_index" : "blogs",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"title" : "ElasticSearch架构",
"category" : "ElasticSearch",
"tags" : [
"ElasticSearch",
"架构"
]
}
}索引文档(Index)
Index 也可以认为是存储文档,不过与Create 不同的是,如果文档ID不存在则会索引新的文档;如果文档ID存在,则会先删除原先的文档,然后索引新的文档,version 递增。
PUT /blogs/_doc/1
{
"title":"ElasticSearch存储",
"category":"ElasticSearch",
"tags":[
"ElasticSearch",
"存储"
]
}更新文档(Update)
Update 不会删除原先的文档,而是真正的数据更新。
POST /blogs/_update/1
{
"doc" : {
"tags" : [
"ES存储",
"存储架构"
]
}
}批量操作(Bulk API)
使用Bulk API 可以在一次请求中,对不同的索引进行操作,其中可以支持 Index、Create、Update、Delete。批量操作的每一个操作是相互独立的,其中一个操作的执行失败不会影响其他的操作。当然返回结果中也包含了每一条操作的结果响应。
POST _bulk
{"index":{"_index":"blogs","_id":"10"}}
{"title":"ElasticSearch聚合","category":"ElasticSearch","tags":["ElasticSearch","聚合"]}
{"delete":{"_index":"blogs","_id":"11"}}
{"create":{"_index":"blogs","_id":"12"}}
{"title":"ElasticSearch映射","category":"ElasticSearch","tags":["ElasticSearch","映射"]}
{"update":{"_index":"blogs","_id":"12"}}
{"doc":{"tags":["ES","映射结构"]}}批量读取(Mget)
批量读取顾名思义就是批量获取数据,可以减少网络开销,提升性能。
GET /_mget
{
"docs": [
{
"_index": "blogs",
"_id": "10"
},
{
"_index": "blogs",
"_id": "11"
},
{
"_index": "blogs",
"_id": "12"
}
]
}批量查询(msearch)
对于不同的索引可以批量查询,如下所示:
POST /blogs/_msearch
{}
{"query":{"match_all":{}},"size":1}
{"index":"users"}
{"query":{"match_all":{}},"size":2}参考:《ElasticSearch技术解析与实战》、《极客时间:ElasticSearch核心技术与实战》



