分区重分配指的是将分区的副本重新分配到不同的代理节点上。如果ZK节点中分区的副本的新副本集合和当前分区副本集合相同,这个分区就不需要重新分配了。
分区重分配是通过监听ZK的 /admin/reassign_partitions 节点触发的,Kafka也提供了相应的脚本工具进行分区重分配,使用方法如下:
./kafka-reassign-partitions.sh --zookeeper XXX --reassignment-json-file XXX.json --execute
其中 XXX.json 是分区重分配的JSON文件,格式如下:
{
"version":1,
"partitions":[
{"topic":"product", "partition":0, "replicas":[4,5,6]},
{"topic":"product", "partition":1, "replicas":[1,2,3]},
{"topic":"product", "partition":4, "replicas":[4,5,6]}
]
}假设主题 product 的分区数只有 {P0, P1},当执行上面的脚本时。此时会发现P4的分区对于 product 主题根本就不存在,此时就会忽略掉P4的副本迁移。对于P0和P1的副本重分配,可以简单的理解为下面的过程。
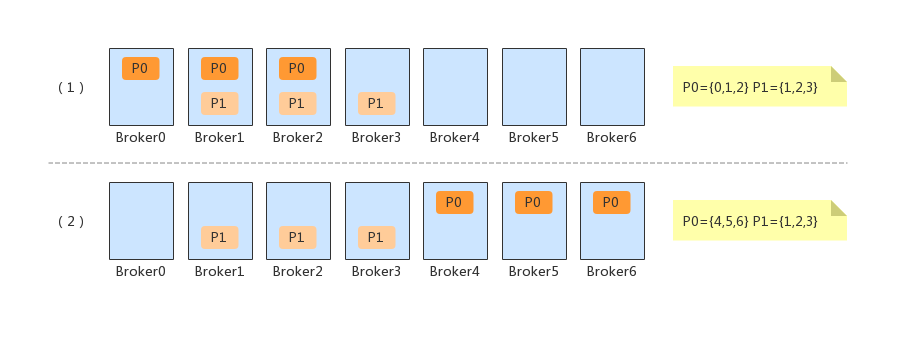
分区重分配命令接收
当使用脚本提交分区重分配时,接收命令的是 kafka.admin.ReassignPartitionsCommand#executeAssignment():
def executeAssignment(zkClient: KafkaZkClient, adminClientOpt: Option[JAdminClient], reassignmentJsonString: String, throttle: Throttle, timeoutMs: Long = 10000L) {
val (partitionAssignment, replicaAssignment) = parseAndValidate(zkClient, reassignmentJsonString)
val adminZkClient = new AdminZkClient(zkClient)
val reassignPartitionsCommand = new ReassignPartitionsCommand(zkClient, adminClientOpt, partitionAssignment.toMap, replicaAssignment, adminZkClient)
// 如果当前有正在执行中的分区重分配,则终止当前提交
if (zkClient.reassignPartitionsInProgress()) {
println("There is an existing assignment running.")
reassignPartitionsCommand.maybeLimit(throttle)
} else {
printCurrentAssignment(zkClient, partitionAssignment.map(_._1.topic))
if (throttle.interBrokerLimit >= 0 || throttle.replicaAlterLogDirsLimit >= 0)
println(String.format("Warning: You must run Verify periodically, until the reassignment completes, to ensure the throttle is removed. You can also alter the throttle by rerunning the Execute command passing a new value."))
/** 更新重分配数据至ZK */
if (reassignPartitionsCommand.reassignPartitions(throttle, timeoutMs)) {
println("Successfully started reassignment of partitions.")
} else
println("Failed to reassign partitions %s".format(partitionAssignment))
}
}提交命令时,如果分区重分配还在进行,那么本次无法提交,意味着当前只能有一个执行的分区重分配。
重分配监听执行整体流程
当 /admin/reassign_partitions 被修改后,监听器会触发 PartitionReassignment 事件,其代码执行链如下所示:
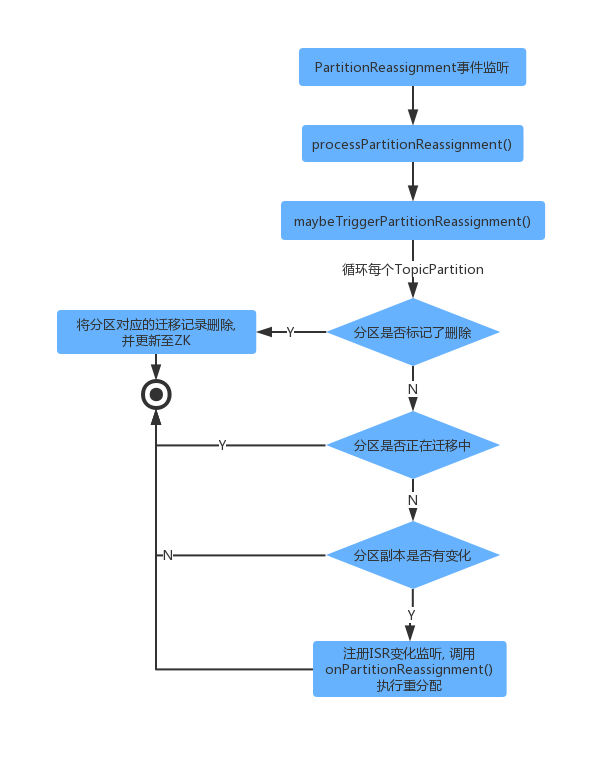
下面我们看一下代码执行流程的展开。
分区重分配流程
控制器事件模型中 PartitionReassignment 事件,会触发调用processPartitionReassignment()。此时会注册监听ZK节点 /admin/reassign_partitions 变化,当重分配策略更新到ZK上时,该监听器就会被触发,然后执行分区重分配逻辑。
case PartitionReassignment =>
processPartitionReassignment()
private def processPartitionReassignment(): Unit = {
if (!isActive) return
/** 注册 /admin/reassign_partitions 节点变化监听 */
if (zkClient.registerZNodeChangeHandlerAndCheckExistence(partitionReassignmentHandler)) {
val partitionReassignment = zkClient.getPartitionReassignment
partitionReassignment.foreach { case (tp, newReplicas) =>
val reassignIsrChangeHandler = new PartitionReassignmentIsrChangeHandler(eventManager, tp)
/** 记录正在迁移的分区副本 */
controllerContext.partitionsBeingReassigned.put(tp, ReassignedPartitionsContext(newReplicas, reassignIsrChangeHandler))
}
maybeTriggerPartitionReassignment(partitionReassignment.keySet)
}
}前置判断
对于是否需要分区重分配,在 maybeTriggerPartitionReassignment() 中做了一些判断取舍,其代码实现如下:
/**
* 如有下面情况发生,则不进行分区重分配:
* 1. Topic设置了删除标识;
* 2. 新副本与已经存在的副本相同;
* 3. 分区所有新分配的副本都不存活;
* 上面的情况发生时, 会输出一条日志, 并从ZK移除该分区副本的重分配记录
*/
private def maybeTriggerPartitionReassignment(topicPartitions: Set[TopicPartition]) {
val partitionsToBeRemovedFromReassignment = scala.collection.mutable.Set.empty[TopicPartition]
topicPartitions.foreach { tp =>
if (topicDeletionManager.isTopicQueuedUpForDeletion(tp.topic)) {
/** 如果topic已经设置了删除,不进行重分配(从需要副本迁移的集合中移除) */
partitionsToBeRemovedFromReassignment.add(tp)
} else {
val reassignedPartitionContext = controllerContext.partitionsBeingReassigned.get(tp).getOrElse {
throw new IllegalStateException(s"Initiating reassign replicas for partition $tp not present in " +
s"partitionsBeingReassigned: ${controllerContext.partitionsBeingReassigned.mkString(", ")}")
}
val newReplicas = reassignedPartitionContext.newReplicas
val topic = tp.topic
val assignedReplicas = controllerContext.partitionReplicaAssignment(tp)
if (assignedReplicas.nonEmpty) {
if (assignedReplicas == newReplicas) {
/** 新副本与已经存在的副本相同,不进行重分配 */
partitionsToBeRemovedFromReassignment.add(tp)
} else {
try {
/** 注册ISR变化监听 */
reassignedPartitionContext.registerReassignIsrChangeHandler(zkClient)
/** 设置正在迁移的副本不能删除 */
topicDeletionManager.markTopicIneligibleForDeletion(Set(topic), reason = "topic reassignment in progress")
/** 执行重分配 */
onPartitionReassignment(tp, reassignedPartitionContext)
} catch {
}
}
} else {
/** 分区副本都不存活,不进行重分配 */
partitionsToBeRemovedFromReassignment.add(tp)
}
}
}
removePartitionsFromReassignedPartitions(partitionsToBeRemovedFromReassignment)
}对于前置校验的流程如下:
1、如果topic已经设置了删除,不进行重分配(从需要副本迁移的集合中移除);
2、如果分区副本都不存活,不进行重分配;
3、如果新副本与已经存在的副本相同,不进行重分配;
4、注册ISR变化监听;
5、设置将要迁移的副本为不能删除;
6、调用 onPartitionReassignment() 执行重分配。
执行分区重分配
分区重分配的执行是在 onPartitionReassignment() 中实现的,下面说明一下官方给出的几个技术名词:
RAR:新分配的副本列表;
OAR:原先的分区副本列表;
AR:当前副本列表,随着分配过程不断变化;
RAR-OAR:RAR与OAR的差集,即需要创建、数据迁移的新副本;
OAR-RAR:OAR与RAR的差集,即迁移后需要下线的副本。
重分配的具体代码实现如下所示:
/**
* 当需要进行分区重分配时, 会在[/admin/reassign_partitions]下创建一个节点来触发操作
* RAR: 重新分配的副本, OAR: 分区原副本列表, AR: 当前的分配的副本
*/
private def onPartitionReassignment(topicPartition: TopicPartition, reassignedPartitionContext: ReassignedPartitionsContext) {
val reassignedReplicas = reassignedPartitionContext.newReplicas
if (!areReplicasInIsr(topicPartition, reassignedReplicas)) {
/** 新分配的并没有全在ISR中 */
/** RAR-OAR */
val newReplicasNotInOldReplicaList = reassignedReplicas.toSet -- controllerContext.partitionReplicaAssignment(topicPartition).toSet
/** RAR+OAR */
val newAndOldReplicas = (reassignedPartitionContext.newReplicas ++ controllerContext.partitionReplicaAssignment(topicPartition)).toSet
/** 1.将AR更新为OAR + RAR */
updateAssignedReplicasForPartition(topicPartition, newAndOldReplicas.toSeq)
/** 2.向上面AR(OAR+RAR)中的所有副本发送LeaderAndIsr请求 */
updateLeaderEpochAndSendRequest(topicPartition, controllerContext.partitionReplicaAssignment(topicPartition), newAndOldReplicas.toSeq)
/** 3.新分配的副本状态更新为NewReplica(第2步中发送LeaderAndIsr时, 新副本会开始创建并且同步数据)*/
startNewReplicasForReassignedPartition(topicPartition, reassignedPartitionContext, newReplicasNotInOldReplicaList)
} else {
/** 4.等待所有的RAR都在ISR中 */
/** OAR - RAR */
val oldReplicas = controllerContext.partitionReplicaAssignment(topicPartition).toSet -- reassignedReplicas.toSet
/** 5.将副本状态设置为OnlineReplica */
reassignedReplicas.foreach { replica =>
replicaStateMachine.handleStateChanges(Seq(new PartitionAndReplica(topicPartition, replica)), OnlineReplica)
}
/** 6.将上下文中的AR设置为RAR */
/** 7.新加入的副本已经同步完成, LeaderAndIsr都更新到最新的结果 */
moveReassignedPartitionLeaderIfRequired(topicPartition, reassignedPartitionContext)
/** 8-9.将旧的副本下线 */
stopOldReplicasOfReassignedPartition(topicPartition, reassignedPartitionContext, oldReplicas)
/** 10.将ZK中的AR设置为RAR */
updateAssignedReplicasForPartition(topicPartition, reassignedReplicas)
/** 11.分区重分配完成, 从ZK /admin/reassign_partitions 节点删除迁移报文 */
removePartitionsFromReassignedPartitions(Set(topicPartition))
/** 12.发送metadata更新请求给所有存活的broker */
sendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq, Set(topicPartition))
/** 如果topic标记了删除, 此时唤醒删除线程*/
topicDeletionManager.resumeDeletionForTopics(Set(topicPartition.topic))
}
}上面代码执行的过程描述如下:
1.将AR更新为OAR+RAR;
2.向上面AR(OAR+RAR)中的所有副本发送LeaderAndIsr请求;
3.新分配的副本状态更新为NewReplica(第2步中发送LeaderAndIsr时, 新副本会开始创建并且同步数据);
4.等待所有的RAR都在ISR中;
5.将副本状态设置为OnlineReplica;
6.将上下文中的AR设置为RAR;
7.新加入的副本已经同步完成, LeaderAndIsr都更新到最新的结果;
8-9.将旧的副本下线;
10.将ZK中的AR设置为RAR;
11.分区重分配完成, 从ZK /admin/reassign_partitions 节点删除迁移报文;
12.发送metadata更新请求给所有存活的broker;
重分配简单描述
通过代码层面看起来不是很好理解,下面简单描述一下执行过程:
1、创建新的副本,开始同步数据,等所有新副本都加入了ISR后,在RAR中进行Leader选举;
2、下线不需要的副本(OAR-RAR),下线完成后将AR(即RAR)信息更新到ZK中;
3、发送LeaderAndIsr给存活broker。
假如初始情况下,分区副本在 {1,2,3} 三个 Broker 上;重分配之后在{4,5,6}上,此时变化过程如下图所示:
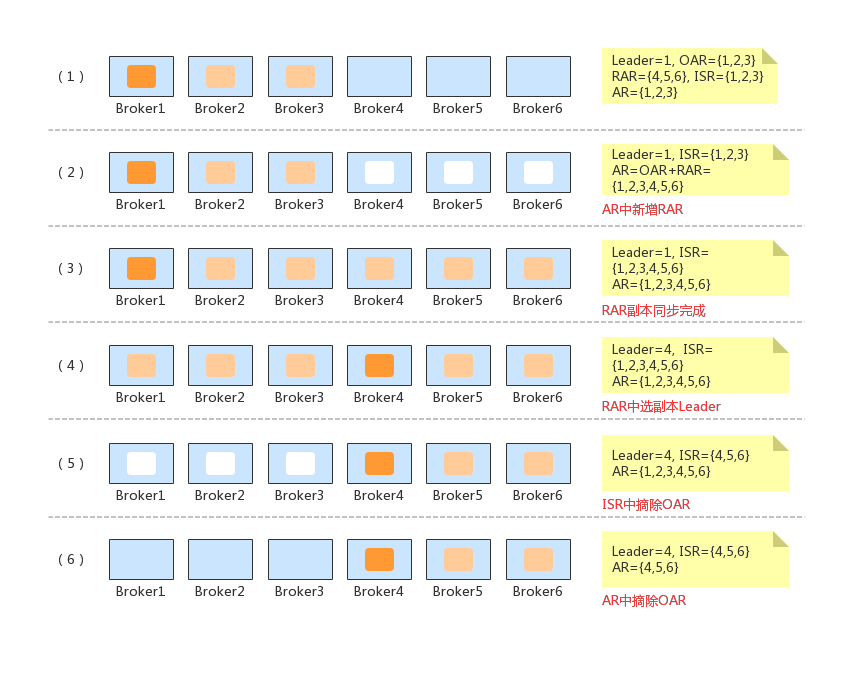
参考:《Kafka技术内幕》、《Apache Kafka 源码剖析》、Kafka源码



