控制器是Kafka的核心组件之一,它的主要作用是在 ZooKeeper 的帮助下协调和管理整个Kafka集群。Kafka 利用ZooKeeper 的领导者选举机制,每个Broker 都会参与竞选主控制器,但是最终只会有一个 Broker 可以成为主控制器。下面我们简单的看一下控制器主要的作用是什么。
1、主题管理:控制器会帮助我们完成Topic 的创建、删除以及增加分区。也就是当执行 kafka-topics.sh 脚本时,大部分的后台工作是由Kafka控制器完成的。
2、分区重分配:是指 kafka-reassign-partitions.sh 脚本对已有主题分区的细粒度的分配功能。
3、Preferred 领导者选举:主要是Kafka为了避免因部分 Broker 的负载过重,而提供的一种换 Leader 的方案。
4、集群成员管理:其中包括新增 Broker、Broker 主动或被动关闭。/brokers/ids/ 下面会存放 Broker 实例的id 临时节点,当我们看到 /brokers/ids 下面有几个节点,就表示有多少个存活的 Broker 实例。当Broker 宕机时,临时节点就会被删除,此时控制器对应的监听器就会感知到Broker 下线,进而完成对应的下线工作。
5、数据服务:控制器上面存放了最全的集群元数据信息,其他 Broker 会定期接收控制器发来的更新请求,从而定期的刷新其元数据缓存数据。
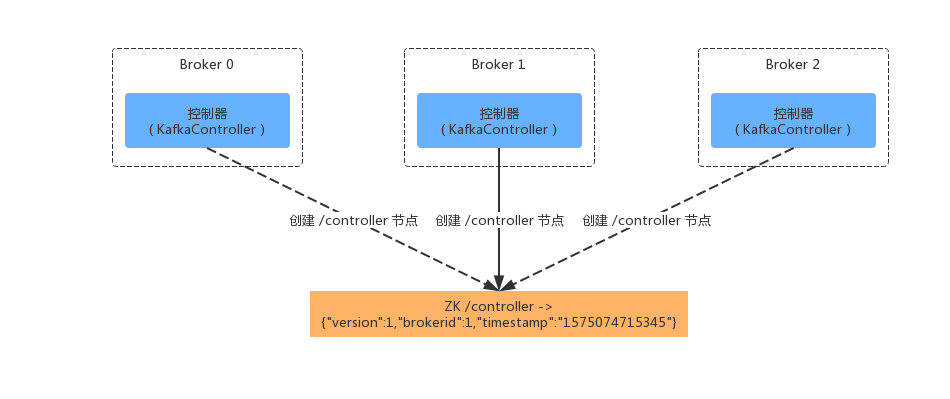
控制器选举
Kafka实现领导者选举的做法是:每个代理节点都会作为ZooKeeper的客户端,向ZooKeeper 服务端尝试创建 /controller 临时节点,但是最终只有 1 个Broker 可以成功创建临时节点。因为 /controller 节点是临时节点,当主控制器出现故障或者会话失效时,临时节点会被删除。此时所有的Broker 都会重新竞选 Leader,也就是尝试创建 /controller 临时节点,如下图所示:
Kafka 控制器将Broker 节点信息存放在 ZooKeeper 的 /controller 节点上。除此之外,集群相关的元数据信息也会存储到 ZooKeeper 中,主控制器会读取 ZooKeeper 中的集群元数据信息,构造出控制器上下文(ControllerContext)。
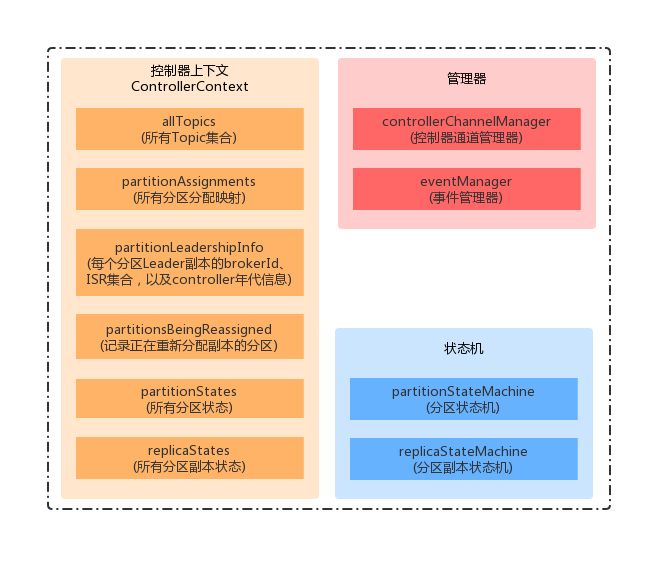
控制器上下文(ControllerContext)
再讲控制器上下文之前,我们先看一下Kafka 在ZK中的存储结构。
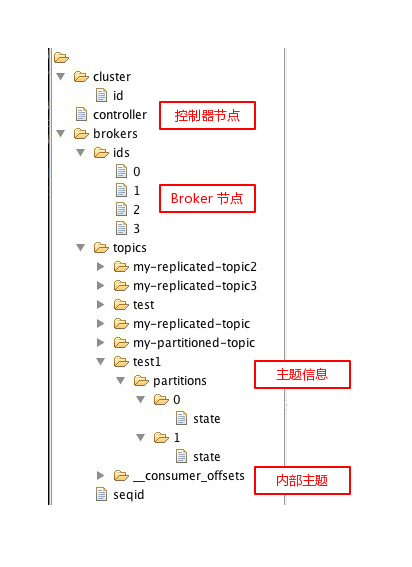
从上面的ZK节点信息可以看出,Kafka的 Broker、主题、分区、控制器等相关信息都存储在其中。当控制器在初始化上下文时,就会读取ZK中的信息初始化ControllerContext 中的相关变量。下面我们看一下 ControllerContext 中的相关成员变量:
class ControllerContext(val zkUtils: ZkUtils) {
/** 管理 controller 与集群中其它 broker 之间的连接 */
var controllerChannelManager: ControllerChannelManager = _
/** 记录正在关闭的 brokerId 集合 */
var shuttingDownBrokerIds: mutable.Set[Int] = mutable.Set.empty
/** controller 的年代信息,初始为 0,每次重新选举之后值加 1 */
var epoch: Int = KafkaController.InitialControllerEpoch - 1
/** 年代信息对应的 ZK 版本,初始为 0 */
var epochZkVersion: Int = KafkaController.InitialControllerEpochZkVersion - 1
/** 集群中全部的 topic 集合 */
var allTopics: Set[String] = Set.empty
/** 记录每个分区对应的 AR 集合 */
var partitionReplicaAssignment: mutable.Map[TopicAndPartition, Seq[Int]] = mutable.Map.empty
/** 记录每个分区的 leader 副本所在的 brokerId、ISR 集合,以及 controller 年代信息 */
var partitionLeadershipInfo: mutable.Map[TopicAndPartition, LeaderIsrAndControllerEpoch] = mutable.Map.empty
/** 记录正在重新分配副本的分区 */
val partitionsBeingReassigned: mutable.Map[TopicAndPartition, ReassignedPartitionsContext] = new mutable.HashMap
/** 记录了正在进行优先副本选举的分区 */
val partitionsUndergoingPreferredReplicaElection: mutable.Set[TopicAndPartition] = new mutable.HashSet
/** 记录了当前可用的 broker 集合 */
private var liveBrokersUnderlying: Set[Broker] = Set.empty
/** 记录了当前可用的 brokerId 集合 */
private var liveBrokerIdsUnderlying: Set[Int] = Set.empty
}
当集群信息变更时,最先感知到的是ZK节点信息,上下文保存了上一次的数据。当两者不一致时,ZK节点关联的监听器触发事件处理时,监听器要对比ZK和Context,找出新增和删除的数据。步骤如下:
(1)ZK节点数据 - ControllerContext 中的数据,表示要新增的数据;
(2)ControllerContext - ZK节点数据,表示要删除的数据;
(3)将 ControllerContext 中的数据,更新为ZK节点中的最新数据;
(4)让控制器分别处理需要新增和删除的节点对应的事件。
事件处理模型
前面我们知道 ControllerContext 上下文中的信息初始化依赖 ZK 中的信息,当ZK中的信息变更时,也要更新ControllerContext 上下文中的信息。比如为某个 Topic 增加了几个分区,此时控制器除了要负责创建分区,还需要更新 ControllerContext。除此之外,还需要将变更的信息同步到其他的 Broker 节点上。这些信息变更可能是监听器触发,也可能是定时任务触发,但最终都会转换为一个个事件,压入到事件队列中去,然后由事件处理线程 (ControllerEventThread)去处理,如下图所示:
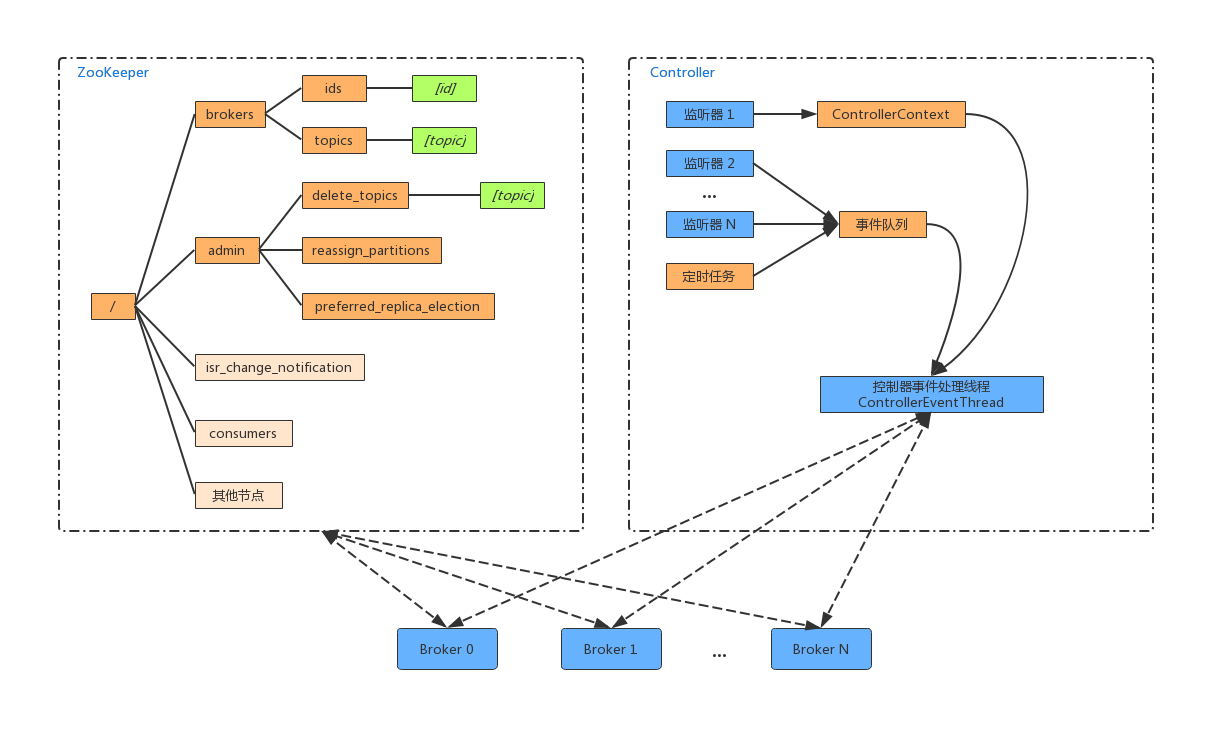
上面的事件模型是在Kafka 0.11.0 版本开始使用的,其大大的减少了控制器多线程的Bug。
ZK监听
Kafka控制器会在初始化上下文之前,向ZK节点注册一些监听器,并在初始化上下文后,执行监听器相关的时间处理。下面列举了常见的ZK节点监听:
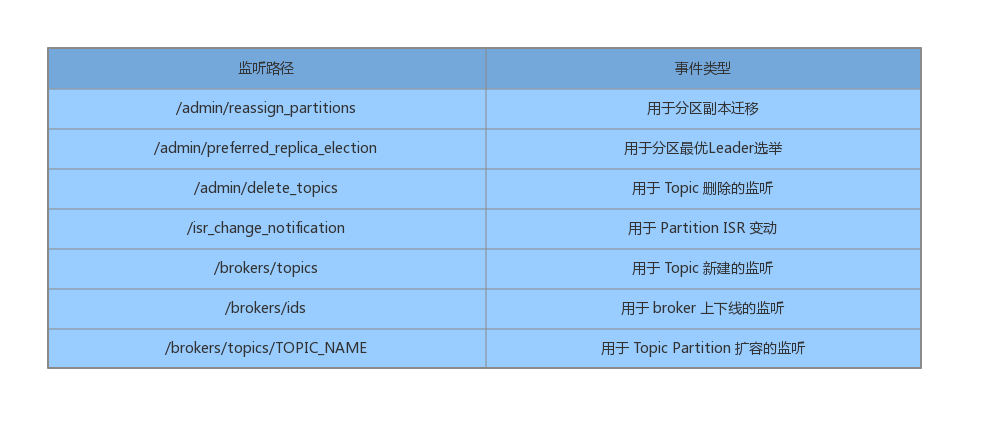
上面以/admin/开头的Node节点与管理操作有关,以/brokers/开头的与代理节点有关。控制初始化时会创建一个副本状态机(ReplicaStateMachine)和一个分区状态机(PartitionStateMachine)。状态机和控制器都是无状态的,它们都可以从共享存储(ZK)中恢复运行时需要的数据。状态机负责状态改变时的事件处理,当控制器发生故障转移时,除了重启控制器,也会重启状态机。故障转移时,不仅要保证集群的状态可以恢复,也要保证状态机可以正常运转。
参考:《Kafka技术内幕》、《Apache Kafka 源码剖析》、Kafka源码



