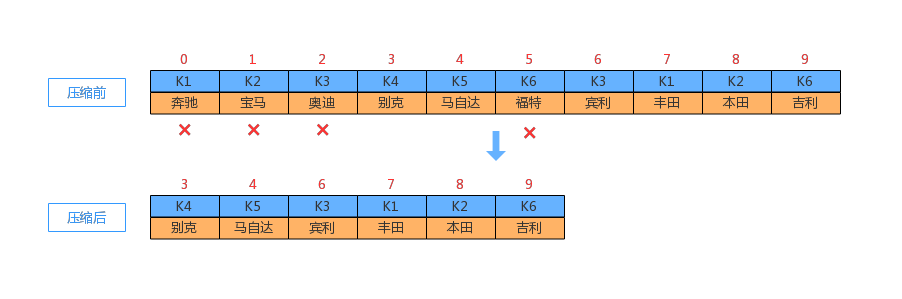
对于存储系统来讲,更新数据通常情况下有 2 种方式:1、直接更新;2、追加的方式更新。第二种做法在更新数据时,不需要读取数据,往往效率比较高。对于Kafka 来讲,消息由Key-Value 组成。在日志压缩时,如果相同的 Key 出现了多次,则会保留最新的那一条,如下图所示:
清理点
基于时间和大小策略的“日志清理”是一种粗粒度的日志保留策略,“日志压缩”则是一种基于每条记录的细粒度日志保留策略。前者的做法是:要么保留整个 LogSegment 要么删除整个 LogSegment;后者的做法是:如果相同的 Key 有新的记录,则有选择的删除旧记录,保证每个 Key 都至少保存有最近的一条记录。那么为了执行日志压缩,我们要解决下面 2 个问题:
1、如何选择参与合并的文件?
除了当前活动的日志分段(activeSegment),Kafka 的日志压缩会选择其他所有的日志分段参与合并操作。之所以要排除 activeSegment,是为了不影响写操作,因为追加消息总是追加到 activeSegment 的末端。
2、选择到文件后,如何压缩?
日志压缩会将旧的日志分段复制到新的日志分段上面。为了降低复制过程中产生的内存开销,在启动清理前会按照“清理点”分为日志头部和尾部,如下图所示:
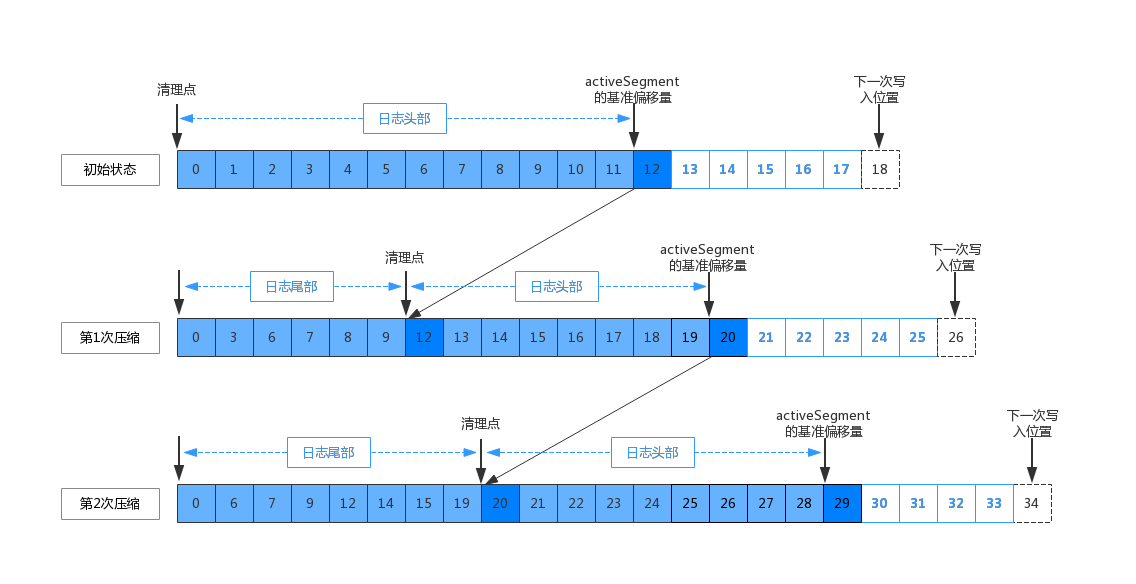
1、第一次清理,清理点的位置等于0,日志头部的范围从 0~12 之间。
2、第一次压缩后,清理点更新为12。后续压缩的范围为,日志的头部和尾部,如上图所示。
3、第二次压缩后,清理点更新为20,然后循环以上步骤。
下面我们来思考一下另外一个问题,就是Broker 在压缩日志的同时,客户端也在读取日志。此时就可能出现下面两种情况了:
1、客户端读取日志时,读取到的偏移片段,此时还没有被压缩过。此时客户端可以读取到生产者发送的全部日志内容。
2、由于客户端拉取速度比较慢,Broker 端的压缩先于客户端的读取,此时客户端读取到的日志就是经过压缩过之后的数据了。此时使用者可能需要根据业务场景,来决定是否可以接受这种场景了。
删除点(墓碑标记)
日志压缩还需要考虑删除消息的场景。此时如果有一条带有 Key 的消息,但是 Value 为 null,则表示这条消息(包含自己)之前的所有消息都需要删除,这也就是所谓的"墓碑标记"。
Kafka 每条消息都有可能有多个副本,消息的复制可能会存在延迟和失败。为了保证墓碑标记之前的所有消息都删除掉,除了将标记追加到主副本的日志分段上,也需要复制并保存到其他节点的副本上。墓碑标记会在日志分段中存储一段时间,最后在指定的超时时间过后会被删除掉。
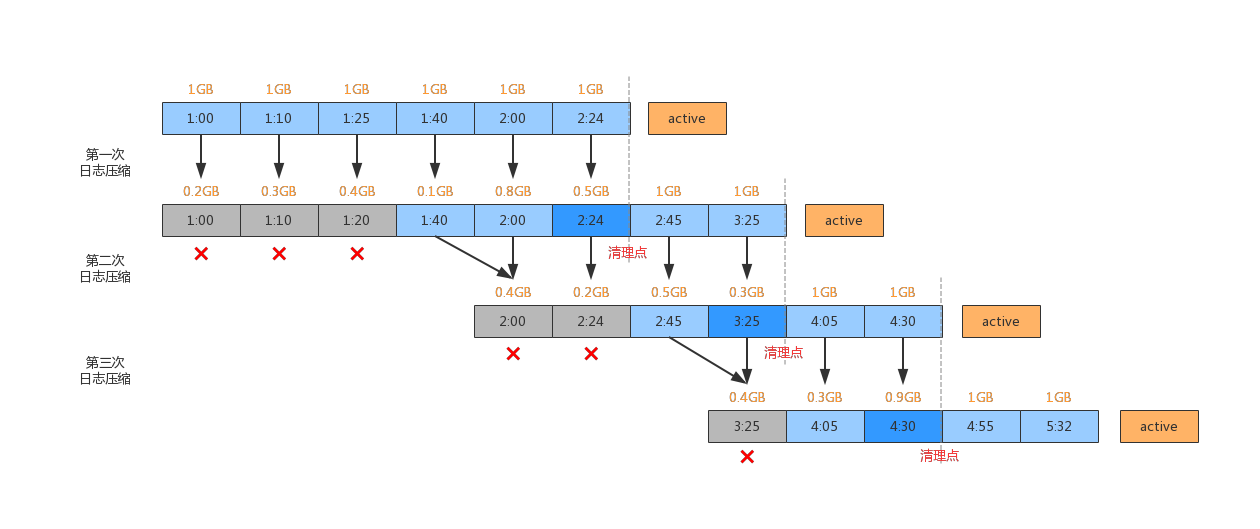
如上图所示,日志压缩会将上一次压缩后的多个小文件合并为一组,压缩为新的文件。图中的时间表示日志分段的修改时间,并且上面也标识了文件的大小。一次完整的日志压缩过程包括:压缩前选择日志分段、压缩时复制消息、压缩后生成新文件。压缩后不会更新每条消息的偏移量,也不会更改文件的最近修改时间。
清理点之前的日志,我们可以认为是待删除日志(墓碑日志),但是是否可以删除,还需要再次判断一下。保留墓碑日志分段简单点说就是,从检查点往前的24小时(默认配置)以内的数据将会被保留。也就是说超过 24 小时的消息将会被删除。这个 24 小时的阈值是由 Broker 端参数 log.cleaner.delete.retention.ms 决定的。为了简化流程,上图中假设这个阈值为1小时。下面简单的描述一下压缩和清理的流程。
1、第一次日志压缩,[1:00~2:24] 区间段的日志分段分别被压缩,压缩结果并没有删除日志分段。此时清理点变为[2:24]分段的末端。
2、第二次日志压缩,考虑了墓被标记是否需要保留。清理点前的日志分段[2:24]向前推1小时,超过1小时的数据将会被删除,也就是[1:00~1:20] 区间段的 3 个日志分段。
3、第三次日志压缩,清理点变为[3:25] 分段的末端,此时[2:00~2:24] 区间段的 2 个日志分段将会被删除。
上面的压缩和清理过程还有一点需要注意的是,清理点之前的日志是按分组的形式进行删除和压缩的。分组的策略为:1、按照日志分段的顺序遍历,每组占用空间大小不超过 segmentSize (log.segments.size, 默认1GB) 的设置值,2、索引文件占用大小之和不能超过 maxIndexSize (log.index.interval.bytes, 默认10MB)的设置值。3、同一个组的日志分段清理后,只会生成1个新的日志分段。
参考:《Kafka技术内幕》、《Apache Kafka 源码剖析》、Kafka源码



