Kafka 的日志管理负责日志的创建、检索、清理,和日志相关的读写操作则交给日志实例去处理。每个 TopicPartition 都对应一个物理层面上的 log 实例,LogManager 使用了logs 管理了分区对应的日志实例。简化后的代码结构如下所示:
private val currentLogs = new Pool[TopicPartition, Log]()
/**
* 根据分区编号创建 log 实例, 并加入 log 映射表
*/
def getOrCreateLog(topicPartition: TopicPartition, config: LogConfig, isNew: Boolean = false, isFuture: Boolean = false): Log = {
logCreationOrDeletionLock synchronized {
getLog(topicPartition, isFuture).getOrElse {
try {
val dir = {
if (isFuture)
new File(logDir, Log.logFutureDirName(topicPartition))
else
new File(logDir, Log.logDirName(topicPartition))
}
Files.createDirectories(dir.toPath)
val log = Log(
dir = dir,
config = config,
logStartOffset = 0L,
recoveryPoint = 0L,
maxProducerIdExpirationMs = maxPidExpirationMs,
producerIdExpirationCheckIntervalMs = LogManager.ProducerIdExpirationCheckIntervalMs,
scheduler = scheduler,
time = time,
brokerTopicStats = brokerTopicStats,
logDirFailureChannel = logDirFailureChannel)
if (isFuture)
futureLogs.put(topicPartition, log)
else
currentLogs.put(topicPartition, log)
log
} catch {
// ...
}
}
}
}
Kafka 服务端实例的数据目录配置项(log.dirs)可以设置多个目录。如果 log.dirs = /data/kafka_log/logs1,/data/kafka_log/logs2,表示该服务端实例有 2 个数据目录。如下图所示,每个 TopicPartition 都对应一个文件夹,在其同级目录下面还有一些检查点文件,下图是经过删减之后的目录和文件列表。
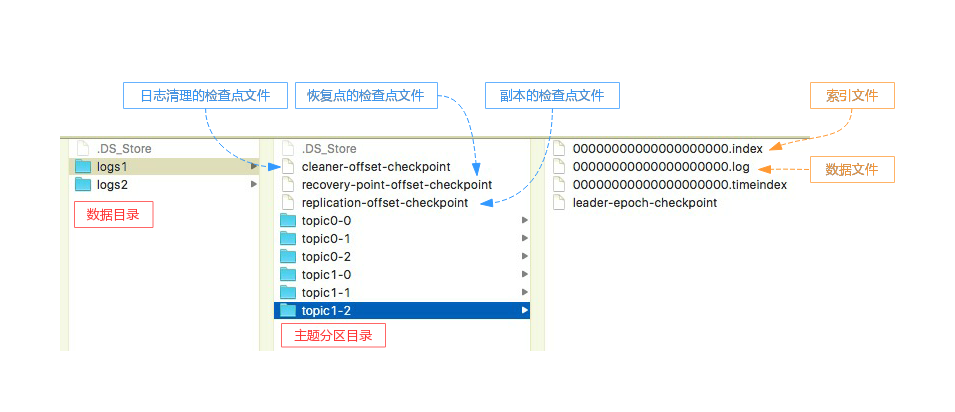
Kafka 启动时会创建一个 LogManager 对象,并且执行 loadLogs() 方法加载所有的 log,而每一个 log 也会调用 loadSegments() 加载所有的 LogSegment。由于这个过程比较慢,所以 LogManager 用异步线程池的方式为每一个 Log 的加载都创建了一个单独的线程,相关代码如下。
/**
* 创建日志管理类, 就会立即调用该方法, 加载所有的日志
* Recover and load all logs in the given data directories
*/
private def loadLogs(): Unit = {
info("Loading logs.")
val startMs = time.milliseconds
val threadPools = ArrayBuffer.empty[ExecutorService]
val offlineDirs = mutable.Set.empty[(String, IOException)]
val jobs = mutable.Map.empty[File, Seq[Future[_]]]
/** 处理每一个数据目录 */
for (dir <- liveLogDirs) {
try {
/** 每一个数据目录都有一个线程池 */
val pool = Executors.newFixedThreadPool(numRecoveryThreadsPerDataDir)
threadPools.append(pool)
val cleanShutdownFile = new File(dir, Log.CleanShutdownFile)
if (cleanShutdownFile.exists) {
debug(s"Found clean shutdown file. Skipping recovery for all logs in data directory: ${dir.getAbsolutePath}")
} else {
// log recovery itself is being performed by `Log` class during initialization
brokerState.newState(RecoveringFromUncleanShutdown)
}
var recoveryPoints = Map[TopicPartition, Long]()
try {
/** 读取检查点文件内容 */
recoveryPoints = this.recoveryPointCheckpoints(dir).read
} catch {
case e: Exception =>
warn(s"Error occurred while reading recovery-point-offset-checkpoint file of directory $dir", e)
warn("Resetting the recovery checkpoint to 0")
}
var logStartOffsets = Map[TopicPartition, Long]()
try {
logStartOffsets = this.logStartOffsetCheckpoints(dir).read
} catch {
case e: Exception =>
warn(s"Error occurred while reading log-start-offset-checkpoint file of directory $dir", e)
}
val jobsForDir = for {
/** dir 是指数据目录, dirContent 是数据目录下所有的日志目录 */
dirContent <- Option(dir.listFiles).toList
/** logDir 是日志目录(主题分区) */
logDir <- dirContent if logDir.isDirectory
} yield {
/** 每个日志目录都有一个线程 */
CoreUtils.runnable {
try {
/** 创建 log 实例, 完成后加入 LogManager 的映射表 */
loadLog(logDir, recoveryPoints, logStartOffsets)
} catch {
case e: IOException =>
offlineDirs.add((dir.getAbsolutePath, e))
error(s"Error while loading log dir ${dir.getAbsolutePath}", e)
}
}
}
/** 提交任务 */
jobs(cleanShutdownFile) = jobsForDir.map(pool.submit)
} catch {
case e: IOException =>
offlineDirs.add((dir.getAbsolutePath, e))
error(s"Error while loading log dir ${dir.getAbsolutePath}", e)
}
}
try {
for ((cleanShutdownFile, dirJobs) <- jobs) {
dirJobs.foreach(_.get)
try {
cleanShutdownFile.delete()
} catch {
case e: IOException =>
offlineDirs.add((cleanShutdownFile.getParent, e))
error(s"Error while deleting the clean shutdown file $cleanShutdownFile", e)
}
}
offlineDirs.foreach { case (dir, e) =>
logDirFailureChannel.maybeAddOfflineLogDir(dir, s"Error while deleting the clean shutdown file in dir $dir", e)
}
} catch {
case e: ExecutionException =>
error(s"There was an error in one of the threads during logs loading: ${e.getCause}")
throw e.getCause
} finally {
threadPools.foreach(_.shutdown())
}
info(s"Logs loading complete in ${time.milliseconds - startMs} ms.")
}LogManager 是采用线程池提交任务,但是每个任务本身的执行是阻塞的。也就是只有在 log 加载完成之后,才会被加到 logs 映射表中。如果没有加载完所有日志,loadLogs() 也就不能返回。LogManager 加载完成后,KafkaServer 会调用LogManager.startup() 启动下面 4 个后台的管理线程。前面 2 个可以看做日志刷新策略,后面 2 个可以看做日志清理策略。相关代码如下:
/**
* LogManager 启动后,会有多个后台定时任务
*/
def startup() {
if (scheduler != null) {
/** 定时清理失效的日志分段, 并维护日志的大小 */
scheduler.schedule("kafka-log-retention", cleanupLogs _, delay = InitialTaskDelayMs, period = retentionCheckMs, TimeUnit.MILLISECONDS)
/** 定时刷新还没有写到磁盘的日志 */
scheduler.schedule("kafka-log-flusher", flushDirtyLogs _, delay = InitialTaskDelayMs, period = flushCheckMs, TimeUnit.MILLISECONDS)
/** 定时将所有数据目录, 所有日志的检查点写到检查点文件中 */
scheduler.schedule("kafka-recovery-point-checkpoint", checkpointLogRecoveryOffsets _, delay = InitialTaskDelayMs, period = flushRecoveryOffsetCheckpointMs, TimeUnit.MILLISECONDS)
/** 定时将日志开始偏移量写入到检查点文件中 */
scheduler.schedule("kafka-log-start-offset-checkpoint", checkpointLogStartOffsets _, delay = InitialTaskDelayMs, period = flushStartOffsetCheckpointMs, TimeUnit.MILLISECONDS)
/** 定时删除标记为 delete 的日志 */
scheduler.schedule("kafka-delete-logs", deleteLogs _, delay = InitialTaskDelayMs, unit = TimeUnit.MILLISECONDS)
}
/** 定时压缩日志, 相同 key 不同value 的消息只保存最近一条 */
if (cleanerConfig.enableCleaner)
cleaner.startup()
}我们下面看一下 Kafka 服务端配置文件(server.properties)对 LogManager 后台线程不同的配置项:
############################# 日志基础配置 #############################
# 数据目录列表
log.dirs=/data/kafka-cluster/kafka03/logs
# 启动每个数据目录用来恢复日志的线程数(检查点相关的配置)
num.recovery.threads.per.data.dir=1
############################# 日志刷新策略 #############################
# 追加的消息立即写到文件系统的操作系统页面缓存中,有下面2种策略会刷新磁盘。超过10000条消息,或者经过1秒就调用一次 fsync,将页面缓存的数据刷新到磁盘
#log.flush.interval.messages=10000
#log.flush.interval.ms=1000
############################# 日志保留策略 #############################
# 日志清理也有2种策略。如果是时间策略,表示日志最多只会保存168小时,即7天;
# 如果是大小策略,超过这个大小后,多余的数据会被删除,保证日志不能太大
log.retention.hours=168
#log.retention.bytes=1073741824
# 日志分段超过1GB,会创建新的日志分段
log.segment.bytes=1073741824
# 每5分钟检查是否有要删除的日志
log.retention.check.interval.ms=300000检查点文件
Kafka 服务端实例可以用多个数据目录存储所有分区日志,每个数据目录都有一个全局检查点文件(恢复检查点文件),该文件会存储这个数据目录下所有 log 的检查点信息。检查点表示日志已经刷新到磁盘的位置,其主要用于故障恢复,下面看一下相关代码:
/** LogManager不仅管理了所有的 Log,还管理了所有的Log检查点 */
private val futureLogs = new Pool[TopicPartition, Log]()
private var recoveryPointCheckpoints = liveLogDirs.map(dir =>
(dir, new OffsetCheckpointFile(new File(dir, RecoveryPointCheckpointFile), logDirFailureChannel))).toMap
/** 通常所有数据目录都会一起执行,不会专门操作某一个数据目录的检查点文件 */
def checkpointLogRecoveryOffsets() {
logsByDir.foreach { case (dir, partitionToLogMap) =>
liveLogDirs.find(_.getAbsolutePath.equals(dir)).foreach { f =>
checkpointRecoveryOffsetsAndCleanSnapshot(f, partitionToLogMap.values.toSeq)
}
}
}
/** 对数据目录下的所有日志(即所有分区),将其检查点写入检查点文件 */
private def checkpointLogRecoveryOffsetsInDir(dir: File): Unit = {
for {
partitionToLog <- logsByDir.get(dir.getAbsolutePath)
checkpoint <- recoveryPointCheckpoints.get(dir)
} {
checkpoint.write(partitionToLog.mapValues(_.recoveryPoint))
}
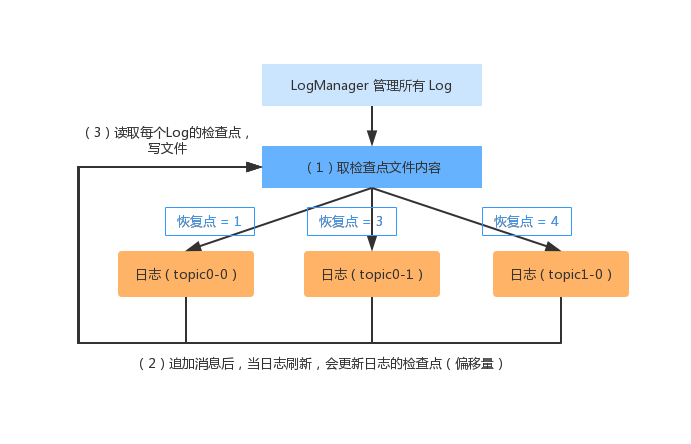
}检查点文件在LogManager 和 Log 实例的运行过程中起到了重要的作用,具体步骤如下:
(1)Kafka 启动时创建 LogManager,读取检查点文件,并把每个分区对应的检查点作为对日志的恢复点(recoveryPoint),最后创建分区对应的Log实例。
(2)消息追加到分区对应的日志,在刷新日志时,将最新的偏移量作为日志的检查点。
(3)LogManager 会启动一个定时任务,读取所有日志的检查点,并写入全局的检查点文件。
刷新日志
LogManager 启动时会定时调用 flushDirtyLogs() ,定期将页面缓存中的数据真正刷写到磁盘文件中。日志在未刷写之前,数据保存在操作系统的页面缓存中,这比直接将数据写到磁盘快得多。这种做法同时也意味着:如果数据还没来得及刷写到磁盘上,服务端实例崩溃了,这就会造成数据丢失。前面我们提到,在Kafka 中有两种刷盘策略:
1、时间策略(log.flush.interval.ms): 配置调度周期,默认无限大,也就是默认选择大小策略。
2、大小策略(log.flush.interval.messages): 配置当未刷新的消息数超过该值时,进行刷新。
/**
* 日志管理器在启动时, 会启动一个定时刷写所有日志的任务
*/
private def flushDirtyLogs(): Unit = {
for ((topicPartition, log) <- currentLogs.toList ++ futureLogs.toList) {
try {
/** 虽然是定时的, 但是每个日志的最近刷新时间不同, 下一次刷新时间也不同 */
val timeSinceLastFlush = time.milliseconds - log.lastFlushTime
if(timeSinceLastFlush >= log.config.flushMs)
log.flush
} catch {
case e: Throwable =>
error(s"Error flushing topic ${topicPartition.topic}", e)
}
}
}
/**
* 获取最近的偏移量, 刷新上一次检查点到最近偏移量之间的所有日志分段
*/
def flush(): Unit = flush(this.logEndOffset)
def flush(offset: Long) : Unit = {
if (offset <= this.recoveryPoint)
return
/** 刷新恢复点到最新偏移量之间的所有日志分段 */
for (segment <- logSegments(this.recoveryPoint, offset))
/** 刷新数据文件和索引文件 (调用操作系统的fsync) */
segment.flush()
lock synchronized {
checkIfMemoryMappedBufferClosed()
if (offset > this.recoveryPoint) {
this.recoveryPoint = offset
/** 更新最近的刷新时间 */
lastFlushedTime.set(time.milliseconds)
}
}
}
}通过上面的代码可以看出,刷盘只是按照时间策略去刷盘的。那么什么时候是按照大小去判断呢?大家应该能猜到肯定是追加消息的时候。那么我们看一下Log.append() 方法的简化实现:
/**
* 追加消息到日志,必要时创建日志分段,并 flush 到磁盘
*/
private def append(records: MemoryRecords, isFromClient: Boolean, interBrokerProtocolVersion: ApiVersion, assignOffsets: Boolean, leaderEpoch: Int): LogAppendInfo = {
maybeHandleIOException(s"Error while appending records to $topicPartition in dir ${dir.getParent}") {
// they are valid, insert them in the log
lock synchronized {
/** 可能需要滚动创建分段 */
val segment = maybeRoll(validRecords.sizeInBytes, appendInfo)
/** 追加消息到当前分段 */
segment.append(largestOffset = appendInfo.lastOffset,
largestTimestamp = appendInfo.maxTimestamp,
shallowOffsetOfMaxTimestamp = appendInfo.offsetOfMaxTimestamp,
records = validRecords)
/** 修改最新的"下一个偏移量" */
updateLogEndOffset(appendInfo.lastOffset + 1)
/** 写入磁盘 */
if (unflushedMessages >= config.flushInterval)
flush()
appendInfo
}
}
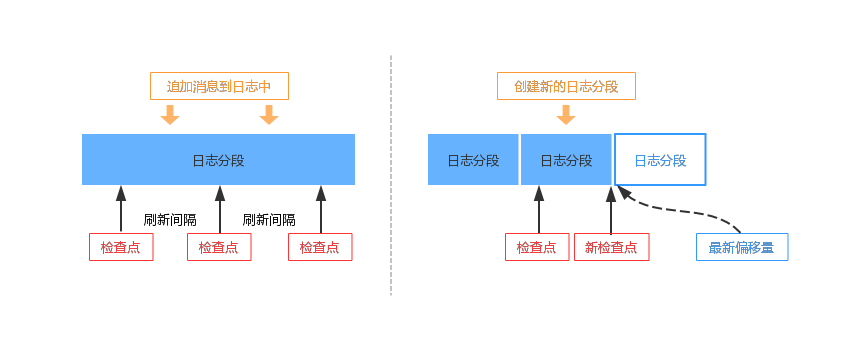
}消息追加到日志中,有下面两种场景会发生刷新日志的动作。
1、新创建一个日志分段,立即刷新旧的日志分段。
2、日志中未刷新的消息数量超过 log.flush.interval.messages 配置项的值。
刷新日志的参数是日志最新偏移量 (logEndOffset),它要和日志中现有的检查点位置 (recoveryPoint) 比较,只有最新偏移量比检查点位置大才需要刷新。因为一个日志包含多个日志分段,在刷新日志时,会刷新从检查点位置到最新偏移量的所有日志分段,最后更新检查点位置。下面我们看一下,创建新的日志分段和达到 log.flush.interval.messages 阈值的两种情况刷盘。
日志清理
为了控制日志的总大小不超过阈值 ( log.retention.bytes ),日志管理器会定时清理旧的日志分段。日志清理有下面 2 种策略:
1、删除:超过日志的阈值,直接物理删除整个日志分段。
2、压缩:不直接删除日志分段,而是采用合并压缩的方式。
不过通常情况下,我们都是通过 log.retention.hours 来配置 Segment 的保存时间。因为不同的 Topic 对应的分区,数据量大小也不一样。因此如果限制的大小,其保存时间不固定,不利于管理和控制消息。下面我们看一下日志清理的相关代码摘要:
/**
* 日志清除任务 LogManager
*/
def cleanupLogs() {
var total = 0
try {
deletableLogs.foreach {
case (topicPartition, log) =>
/** 清理过期的 segment */
total += log.deleteOldSegments()
val futureLog = futureLogs.get(topicPartition)
if (futureLog != null) {
total += futureLog.deleteOldSegments()
}
}
} finally {
if (cleaner != null) {
cleaner.resumeCleaning(deletableLogs.map(_._1))
}
}
}从上面可以看出,清除日志的具体实现是在 Log.deleteOldSegments() 方法中完成的,下面具体看一下:
/**
* 删除过期日志分段
*/
def deleteOldSegments(): Int = {
if (config.delete) {
deleteRetentionMsBreachedSegments() + deleteRetentionSizeBreachedSegments() + deleteLogStartOffsetBreachedSegments()
} else {
deleteLogStartOffsetBreachedSegments()
}
}
/**
* 清除保存时间满足条件的 segment
*/
private def deleteRetentionMsBreachedSegments(): Int = {
if (config.retentionMs < 0) return 0
val startMs = time.milliseconds
deleteOldSegments((segment, _) => startMs - segment.largestTimestamp > config.retentionMs,
reason = s"retention time ${config.retentionMs}ms breach")
}
/**
* 清除保存大小满足条件的 segment
*/
private def deleteRetentionSizeBreachedSegments(): Int = {
if (config.retentionSize < 0 || size < config.retentionSize) return 0
var diff = size - config.retentionSize
def shouldDelete(segment: LogSegment, nextSegmentOpt: Option[LogSegment]) = {
if (diff - segment.size >= 0) {
diff -= segment.size
true
} else {
false
}
}
deleteOldSegments(shouldDelete, reason = s"retention size in bytes ${config.retentionSize} breach")
}
/**
* 清除不符合 startOff 开始偏移量的 segment
*/
private def deleteLogStartOffsetBreachedSegments(): Int = {
def shouldDelete(segment: LogSegment, nextSegmentOpt: Option[LogSegment]) = nextSegmentOpt.exists(_.baseOffset <= logStartOffset)
deleteOldSegments(shouldDelete, reason = s"log start offset $logStartOffset breach")
}通过上面的代码可以看出,日志的清理工作,会分别从 存活时间、日志大小和不符合起始偏移量 3 个角度去清理。
/**
* 清除相应的 segment 及相应的索引文件
* 其中 predicate 是一个高阶函数,只有返回值为 true 该 segment 才会被删除
*/
private def deleteOldSegments(predicate: (LogSegment, Option[LogSegment]) => Boolean, reason: String): Int = {
lock synchronized {
val deletable = deletableSegments(predicate)
deleteSegments(deletable)
}
}
private def deleteSegments(deletable: Iterable[LogSegment]): Int = {
lock synchronized {
checkIfMemoryMappedBufferClosed()
deletable.foreach(deleteSegment)
maybeIncrementLogStartOffset(segments.firstEntry.getValue.baseOffset)
}
}
private def deleteSegment(segment: LogSegment) {
lock synchronized {
/** 从映射关系表中删除数据 */
segments.remove(segment.baseOffset)
/** 异步删除日志分段, 标记删除 */
asyncDeleteSegment(segment)
}
}参考:《Kafka技术内幕》、Kafka源码



