Kafka 的主副本主要负责消息的读写操作,消费者或者备份副本都会向主副本同步数据。客户端读取主副本的过程又叫做“拉取”,拉取消息时肯定会指定拉取的偏移量。比如前面介绍过的,消费者会根据提交偏移量,或者客户端设置的重置策略,从指定位置拉取消息。客户端还会指定拉取的数据量大小(fetchSize),这个值默认是 max.partition.fetch.bytes 配置项,大小为 1MB。
一个分区对应的日志管理了所有的日志分段,日志保存了基准偏移量和日志分段的映射关系。给定一个偏移量,要读取从指定位置开始的消息集,最多读取 fetchSize 字节。因为 fetchSize 默认只有 1M,而日志分段对应的数据文件大小默认有 1GB,所以通常来说服务端读取日志时,没有必要读取所有日志分段,只需要选择其中的一个分段即可。
日志分段只是一个逻辑的概念,它管理了物理概念的一个数据文件和一个索引文件。读取日志分段时,首先要读取索引文件再读取数据文件。下面是Kafka 服务端的日志文件示意图:
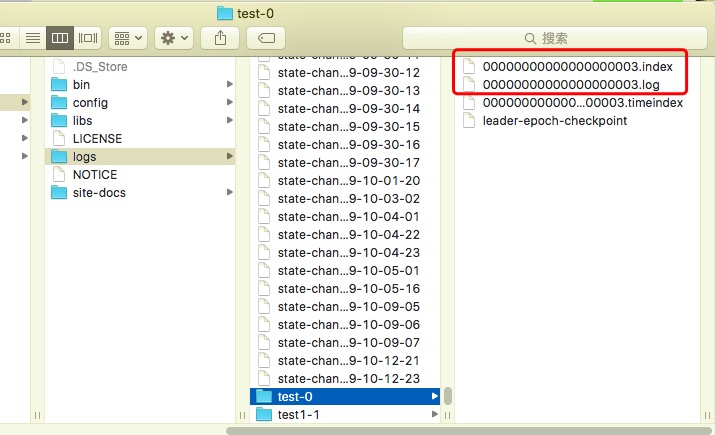
从上图可以看出,日志分段的起始偏移量会作为 数据文件和索引文件的文件名称。下面我们再回顾一下,读取日志的流程。
读取日志分段
我们首先看一下 Kafka 服务端,读取日志分段的代码片段。
/**
* 读取日志分段,返回的日志切片,可能不是精确的以 startOffset 偏移量开始的切片,但是 FetchDataInfo 对象中封装了 startOffset,以便后续遍历切片找到目标消息集合。
*
* @param startOffset 起始offset
* @param maxOffset 结束offset
* @param maxSize 最大字节数
* @param maxPosition 最大物理地址
* @param minOneMessage
*/
def read(startOffset: Long, maxOffset: Option[Long], maxSize: Int, maxPosition: Long = size, minOneMessage: Boolean = false): FetchDataInfo = {
if (maxSize < 0)
throw new IllegalArgumentException(s"Invalid max size $maxSize for log read from segment $log")
/** 获取当前 log 的字节大小 */
val logSize = log.sizeInBytes // this may change, need to save a consistent copy
/** 获取小于等于 startOffset 的最大 offset 对应的物理地址 */
val startOffsetAndSize = translateOffset(startOffset)
/** 如果超出了当前文件,直接返回 null */
if (startOffsetAndSize == null)
return null
val startPosition = startOffsetAndSize.position // 起始物理地址
val offsetMetadata = LogOffsetMetadata(startOffset, this.baseOffset, startPosition)
/** 读取消息的最大字节数 */
val adjustedMaxSize =
if (minOneMessage) math.max(maxSize, startOffsetAndSize.size)
else maxSize
/** 如果读取最大字节数为0,则返回空结果 */
if (adjustedMaxSize == 0)
return FetchDataInfo(offsetMetadata, MemoryRecords.EMPTY)
/** 计算待读取的字节数 */
val fetchSize: Int = maxOffset match {
/** 如果未指定读取消息的结束位置 */
case None =>
/** 直到读取最大的物理地址 */
min((maxPosition - startPosition).toInt, adjustedMaxSize)
/** 如果制定了读取消息的结束位置 */
case Some(offset) =>
/** 如果结束偏移量小于起始偏移量,返回空结果 */
if (offset < startOffset)
return FetchDataInfo(offsetMetadata, MemoryRecords.EMPTY, firstEntryIncomplete = false)
/** 将结束偏移量转换为物理地址 */
val mapping = translateOffset(offset, startPosition)
/** 结束偏移量,超过当前日志,则使用日志最大物理位置 */
val endPosition =
if (mapping == null)
logSize
else
mapping.position
/** 获取最终读取长度 */
min(min(maxPosition, endPosition) - startPosition, adjustedMaxSize).toInt
}
/** 根据起始位置和读取长度, 读取数据文件 */
FetchDataInfo(offsetMetadata, log.slice(startPosition, fetchSize), firstEntryIncomplete = adjustedMaxSize < startOffsetAndSize.size)
}
上面 translateOffset() 方法将起始偏移量(startOffset)转换成LogOffsetPosition 对象,其包含起始偏移量和起始物理位置。物理位置的差值(最大物理位置-起始物理位置)和拉取大小(maxSize)比较取最小值。然后对log 做切片,返回 FileRecords 对象,并最终返回 FetchDataInfo 对象返回。下面我们看一下 FileRecords 对象的生成。
/**
* 返回 records 的一个切片,返回的是一个给定偏移量区间的视图对象
*/
public FileRecords slice(int position, int size) throws IOException {
int end = this.start + position + size;
if (end < 0 || end >= start + sizeInBytes())
end = start + sizeInBytes();
return new FileRecords(file, channel, this.start + position, end, true);
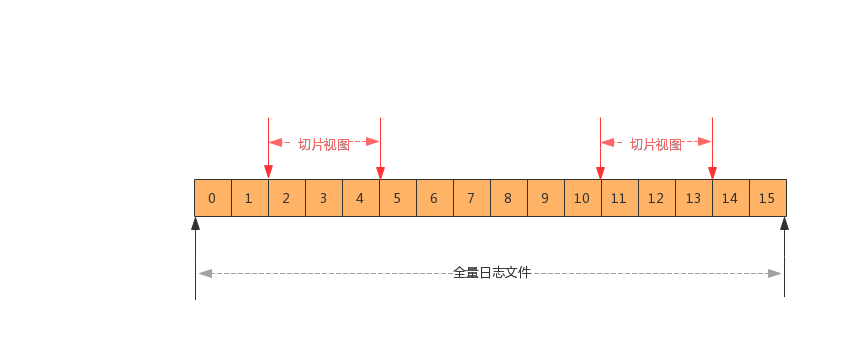
}从上面代码中我们也可以看出,在生成 FileRecords 对象时,并没有读取日志中的内容,仅仅只是对分区日志做了一个“切片视图”,如下图所示。
查找索引文件
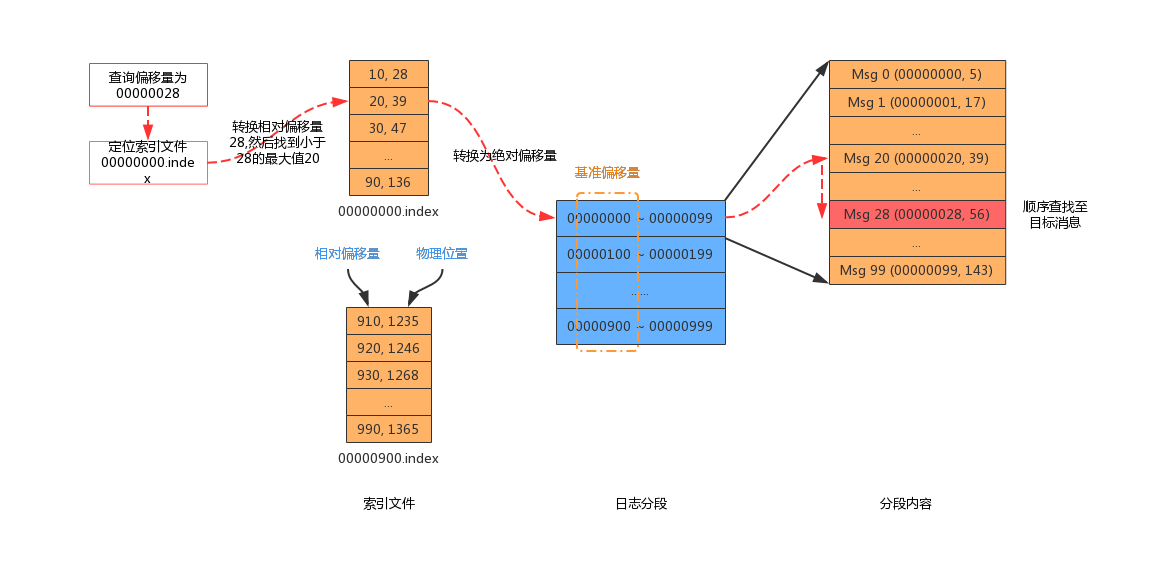
每个日志分段都有一个索引文件和一个数据文件。给定起始偏移量,先调用索引文件的 lookup() 获取小于目标偏移量的最大偏移量的物理位置。然后再调用 searchForOffsetWithSize(),从指定物理位置开始读取每条消息,直到找到目标位置的消息。
/**
* 将起始偏移量转换为起始物理位置
*/
private[log] def translateOffset(offset: Long, startingFilePosition: Int = 0): LogOffsetPosition = {
/** 查询索引文件,返回值包含偏移量和物理位置(索引中最接近目标值的偏移量和物理位置) */
val mapping = offsetIndex.lookup(offset)
/** 返回值对应的物理位置 */
log.searchForOffsetWithSize(offset, max(mapping.position, startingFilePosition))
}首先我们看一下查询索引文件,最后定位到索引中最接近目标值的偏移量和物理位置。索引文件使用内存映射(mmap)的方式加载到内存中。因为在查询的过程中,可能会有新的索引条目添加到索引文件,导致内存映射发生变化,因此要复制出一个字节缓冲区(idx),然后在 idx 上面查询,不需要和底层索引文件发生磁盘读取操作。
/**
* 查询索引文件
*/
def lookup(targetOffset: Long): OffsetPosition = {
maybeLock(lock) {
/** 查询时 mmap 可能发生变化,先复制一个出来 */
val idx = mmap.duplicate
/** 二分查找 */
val slot = largestLowerBoundSlotFor(idx, targetOffset, IndexSearchType.KEY)
if(slot == -1)
OffsetPosition(baseOffset, 0)
else
OffsetPosition(baseOffset + relativeOffset(buffer, n), // 基准偏移量 + 相对偏移量
physical(buffer, n)) // 绝对偏移量在数据文件中对应的物理位置
}
}参考:《Kafka技术内幕》、《极客时间:Kafka核心技术与实战》、Kafka源码



