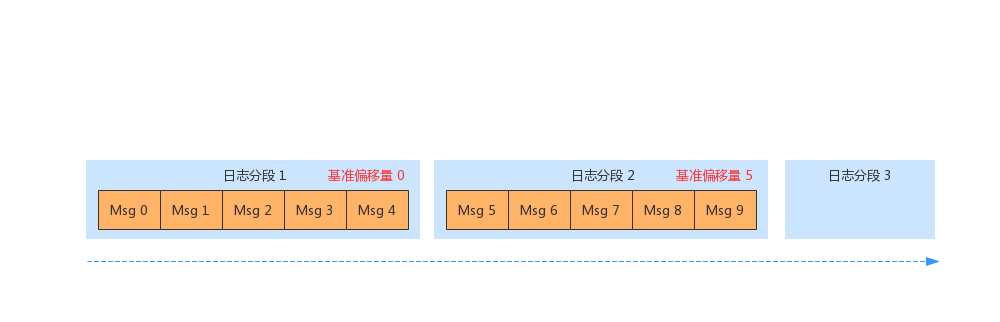
前面我们提到了,服务端存储日志的分区单元是日志分段(LogSegment)。同一个日志分段内,所有消息的偏移量都是递增的,因此可以保证整个分区的偏移量都是递增的。
Kafka 服务端节点每个 TopicPartition 都对应一个 Log,每个 Log 有多个 LogSegment,该 Log 管理分区上面的所有 LogSegment。下面看一下 Log 源码中的核心参数实现:
// Log 所管理的所有 LogSegment 分段,其中 key 是基准偏移量, value 是对应的日志分段
val segments: ConcurrentNavigableMap[Long, LogSegment] = new ConcurrentSkipListMap[Long, LogSegment]
// 加载所有的日志分段, 通常发生在代理节点重启时
loadSegments()
// 添加 LogSegment 到 Log 中
addSegment(segment: LogSegment): LogSegment = this.segments.put(segment.baseOffset, segment)
// 任何时刻都只有 1 个活跃的 LogSegment
def activeSegment = segments.lastEntry.getValue
// 下一个偏移量元数据, 都是从 activeSegment 中获取的
nextOffsetMetadata = LogOffsetMetadata(nextOffset, activeSegment.baseOffset, activeSegment.size)
// LEO 值, 吓一跳消息的偏移量, 取自 Metadata 元数据信息
def logEndOffset: Long = nextOffsetMetadata.messageOffset
下面我们简单看一下上面简化后的代码片段。
activeSegment 被定义为方法,它会获取 segments 的最后一个元素,作为最新的活动 LogSegment。此时如果有新的 LogSegment 被创建,该方法返回的也是最新的日志分段。
nextOffsetMetadata 被定义为一个变量,它的数据依赖于 activeSegment,比如活动分片的下一个偏移量(nextOffset)、活动分段的基准偏移量(baseOffset)、活动分段的大小(size)。
logEndOffset (日志最新偏移量)表示下一条消息的偏移量,它取自 nextOffsetMetadata 的 nextOffset,实际上是活动日志分段的 下一个偏移量值。
对于 nextOffsetMetadata 对象下面详细介绍一下。
(1)追加消息前,使用 nextOffsetMetadata 的消息偏移量,作为这一批消息的起始偏移量。
(2)如果滚动创建了 LogSegment,当前活动的 LogSegment 会指向新创建的日志分段。
(3)追加消息后,更新 nextOffsetMetadata 的消息偏移量,作为下一批消息的起始偏移量。
日志偏移量元数据
日志偏移量元数据是 Log 的一个重要特征,客户端对消息的读写,都会用到这个数据结构。下面我们看一下这个数据结构产生的核心变量。
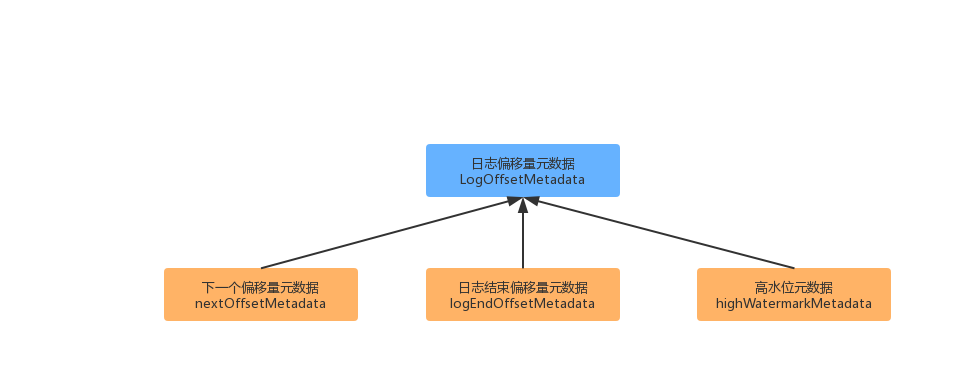
上面展示的 3 个变量当中,其中 nextOffsetMetadata 和 logEndOffsetMetadata 这两个变量可以认为是指到的偏移量是相同的位置,但是因为其针对的客户端不同(一个是生产者、一个是消费者),所以区分开来了。
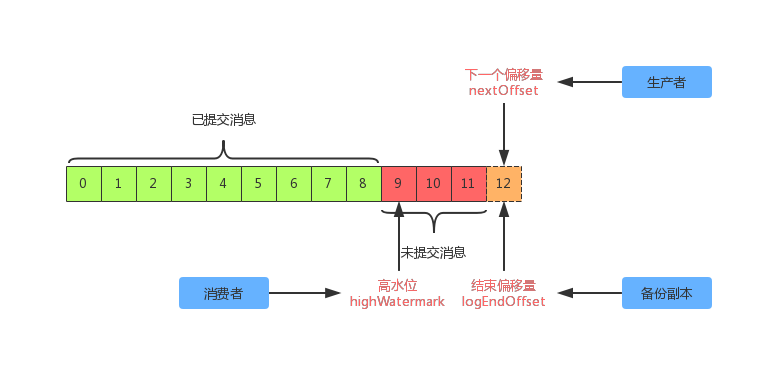
从上面图示可以看出, highWatermark(高水位)会将日志分段分割为“已提交”和“未提交”部分。“已提交”部分对消费者端是可见的,而“未提交”部分则是不可见的,高水位指针指的是 已提交消息+1 的位置。对于 nextOffset 和 logEndOffset 指针则指的是相同的位置,即下一条消息插入的位置。两者的区别是一个是针对于生产者的,另一个是针对于分区备份副本的。
滚动创建日志分段
当为消息分配偏移量之后,消息将会追加到最新的日志分段中。如果当前日志分段放不下新消息,则会采用“滚动”的方式创建一个新的日志分段,并添加其中。
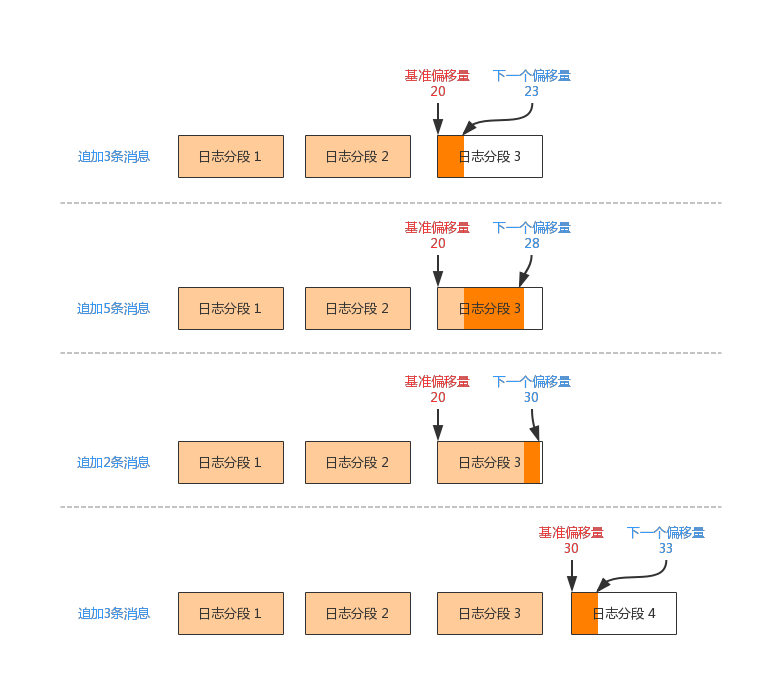
新创建日志分段的基准偏移量取自 logEndOffset,实际上是 nextOffsetMetadata的消息偏移量值(messageOffset),也是当前活动日志分段的下一个偏移量值(nextOffset)。如上图所示:
(1)追加3条消息到日志分段 3,下一个偏移量改为23,基准偏移量20.
(2)追加5条消息到日志分段 3,下一个偏移量改为28,基准偏移量20.
(3)追加2条消息到日志分段 3,下一个偏移量改为30,基准偏移量20.
(4)追加3条消息,此时日志分段 3 已经满了,滚动创建日志分段 4。新日志分段创建后,加入到 segments 后,当前活动的值日分段会指向日志分段 4。下一个偏移量为33,基准偏移量30.
数据文件
LogSegment 包含数据文件和索引文件,基准偏移量是每个日志分段的标识。追加一批消息到日志分段中,每次都会写到对应的数据文件中,同时间隔 indexIntervalBytes 大小才写入一条索引条目到索引文件中。假如一条消息占用 10 字节,每隔 100 字节会写入一个索引条目,也就代表着每 10 条消息才会写入 1 个索引条目。下面看一下 LogSegment.append() 方法的实现摘要。
/**
* 追加消息到日志分段,写入数据文件,并在必要的时候写入索引文件
*/
def append(largestOffset: Long, largestTimestamp: Long, shallowOffsetOfMaxTimestamp: Long, records: MemoryRecords): Unit = {
if (records.sizeInBytes > 0) {
val physicalPosition = log.sizeInBytes()
if (physicalPosition == 0)
rollingBasedTimestamp = Some(largestTimestamp)
ensureOffsetInRange(largestOffset)
// 追加消息到数据文件中
val appendedBytes = log.append(records)
// Update the in memory max timestamp and corresponding offset.
if (largestTimestamp > maxTimestampSoFar) {
maxTimestampSoFar = largestTimestamp
offsetOfMaxTimestampSoFar = shallowOffsetOfMaxTimestamp
}
// 满足条件,追加一条索引
if (bytesSinceLastIndexEntry > indexIntervalBytes) {
offsetIndex.append(largestOffset, physicalPosition)
timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestampSoFar)
bytesSinceLastIndexEntry = 0
}
bytesSinceLastIndexEntry += records.sizeInBytes
}
}索引文件
消息存储到日志分段中,只是简单的追加。此时如果要查询消息,则从日志分段的开始遍历,则就比较低效了。此时建立索引文件就非常有必要了。
写入数据文件的每个消息集,都带有绝对偏移量、消息大小和消息内容。Kafka 创建的索引文件具有以下特性:
(1)索引文件映射偏移量到文件的物理位置,不会对每条消息建立索引,所以是稀疏的。
(2)索引条目的偏移量存储的是相对于“基准偏移量”的“相对偏移量”,不是消息的绝对偏移量(可以减少存储开销)。
(3)索引条目的“相对偏移量”和物理位置各自占用4 个字节,也就是 1 个索引占用 8 字节。消息集的“绝对偏移量”占用的是 8 字节,此时可以减少 4 字节的内存开销。
(4)偏移量是有序的,查询指定偏移量时,可以使用二分查找快读定位偏移量的位置。
(5)当“相对偏移量”在索引中不存在时,找出索引中小于偏移量的最大值,然后定位到物理位置,顺序查找目标偏移量的消息。
(6)使用稀疏索引可以将整个索引文件都放入内存,加快偏移量的查询。
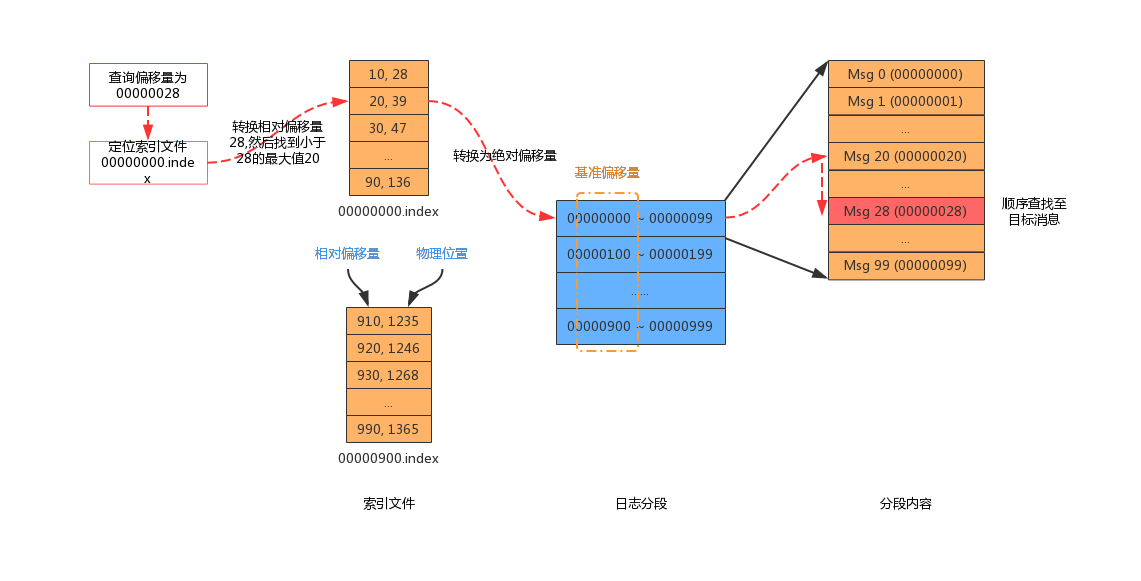
简述一下上面的查找过程,当要拉取绝对偏移量 00000028 的消息时,首先定位到索引文件为 00000000.index。然后转化为相对偏移量 28,之后找到小于28 的最大偏移量 20,找到其物理地址为39,然后定位到具体的物理地址。然后顺序遍历,直到找到绝对偏移量 00000028 的消息。
参考:《Kafka技术内幕》、《极客时间:Kafka核心技术与实战》、Kafka源码



