前面我们介绍了Kafka 生产者客户端的相关原理和网络模型,对于客户端消费者的网络模型,其实现要比生产者的设计还要复杂一些。今天我们主要讲述一下KafkaConsumer 网络模型的主要设计。
消息消费 Demo
public class CustomConsumer {
public static void main(String[] args) {
Properties props = new Properties();
// 定义kakfa 服务的地址,不需要将所有broker指定上
props.put("bootstrap.servers", "127.0.0.1:9092");
// 制定consumer group
props.put("group.id", "g1");
// 是否自动确认offset
props.put("enable.auto.commit", "true");
// 自动确认offset的时间间隔
props.put("auto.commit.interval.ms", "1000");
// key的序列化类
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// value的序列化类
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 定义consumer
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 消费者订阅的topic, 可同时订阅多个
consumer.subscribe(Arrays.asList("test1"));
while (true) {
// 读取数据,读取超时时间为100ms
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}
}
对于消费者而言,在初始化 KafkaConsumer 实例时,通常会为其设置一系列的参数。这其中通常会为消费者指定 groupId,也就是消费者组的ID。通常情况下,多个消费者实例可以设置为同一个groupId。这样同一个 topic 不同分区上面的消息可以分流到不同的消费者实例上面去,从而实现消费的高吞吐。
核心组件
Kafka 消费者端的设计相对生产者要复杂一些,其中一个主要的原因就是,消费者组等相关概念的引入。其中包含了:ConsumerCoordinator、Fetcher、ConsumerNetworkClient 组件,其组合层级示意图如下所示:
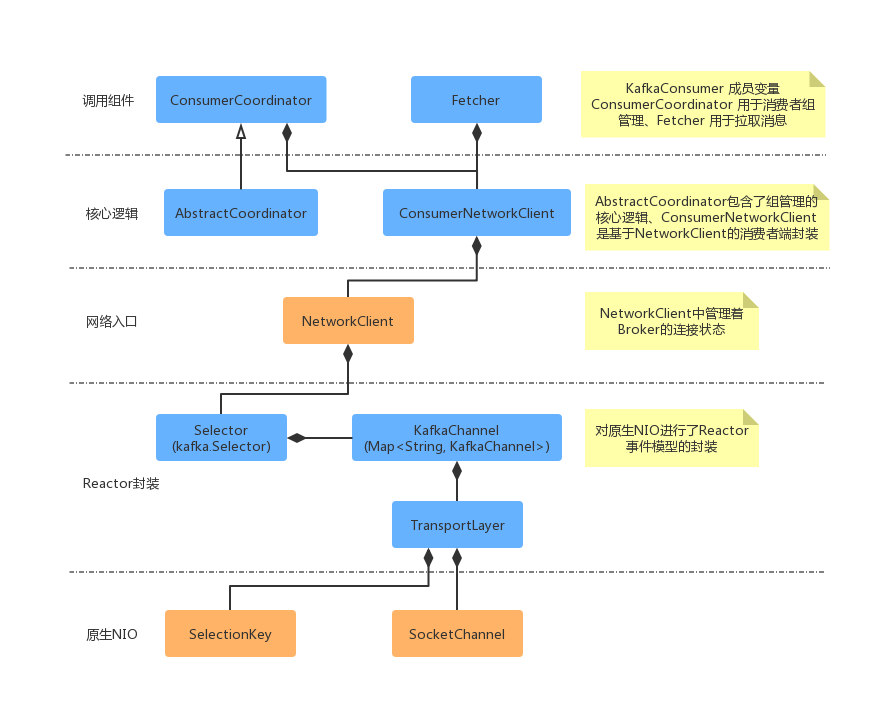
从上面主要组件关系可以看出,KafkaConsumer 有 2 个成员变量 ConsumerCoordinator 和 Fetcher。其中 ConsumerCoordinator 用来和服务端 Coordinator 交互通讯,提供消费者加入group 或者 reblance 的能力,也就是说在 Consumer 获取消息之前,一定是需要在一个 group 当中的。加入 group 完成之后,就是要获取数据了,Fetcher 组件提供了获取消息的能力,在其中做了一些增大吞吐量的优化,将在本篇后面介绍。ConsumerNetworkClient 是 ConsumerCoordinator 和 Fetcher 共同依赖的组件,它是基于 NetworkClient 的进一步封装。实现了Future 模式的结果获取,和线程安全相关的实现。
消费者调用整体流程
下面我们从 KafkaConsumer.poll() 为入口,看一下核心组件之间的调用关系。
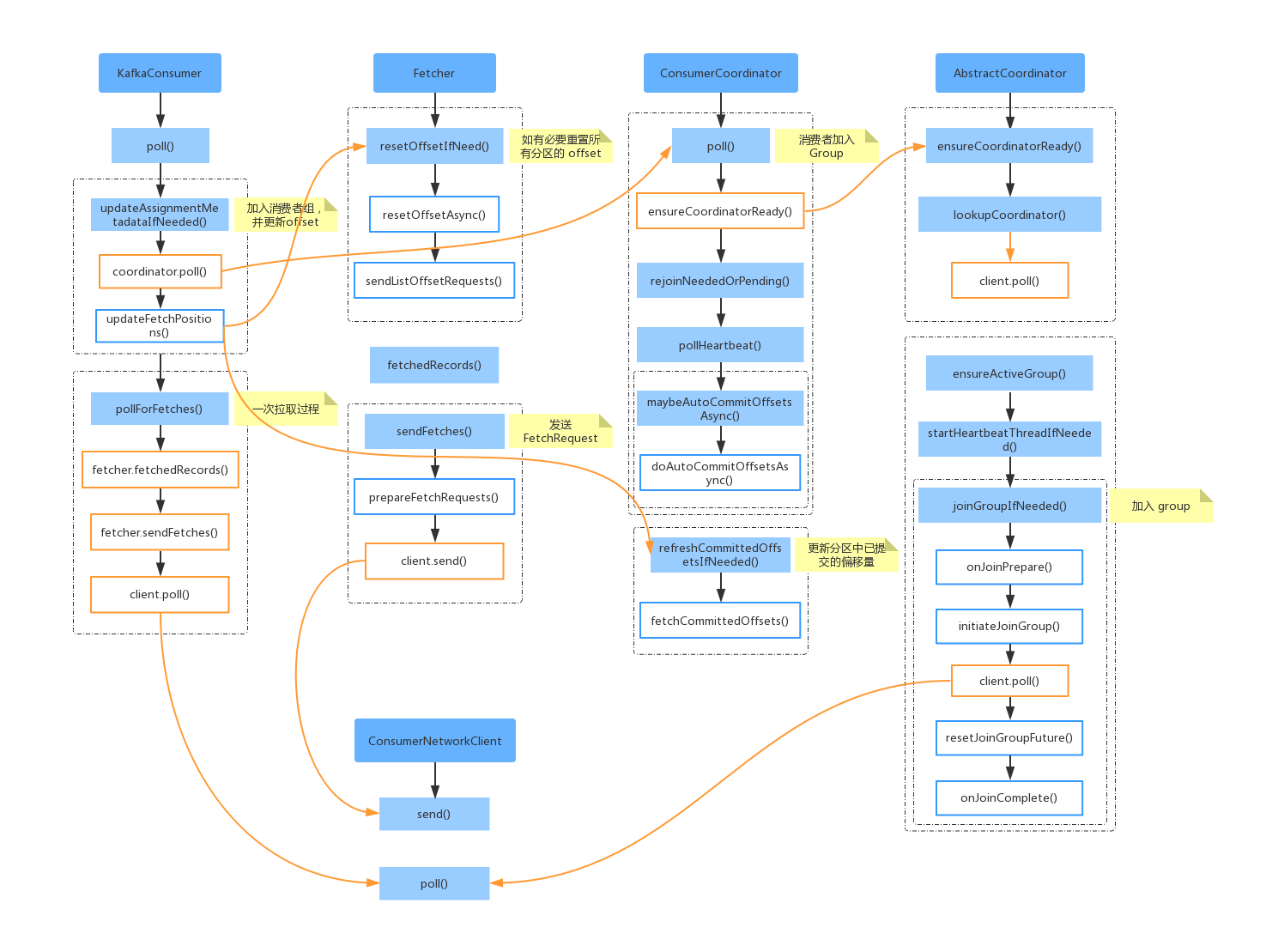 首先当我们调用 KafkaConsumer.poll() 时,首先会调用 updateAssignmentMetadataIfNeeded(),去确认当前消费者是否已经加入group。其中消费者组的协调工作是由 ConsumerCoordinator 组件提供能力的。之后会调用 pollForFetches() 执行消息拉取,拉取的工作是委派给 Fetcher 组件实现的。下面我们详细分析一下整体流程图中的实现。
首先当我们调用 KafkaConsumer.poll() 时,首先会调用 updateAssignmentMetadataIfNeeded(),去确认当前消费者是否已经加入group。其中消费者组的协调工作是由 ConsumerCoordinator 组件提供能力的。之后会调用 pollForFetches() 执行消息拉取,拉取的工作是委派给 Fetcher 组件实现的。下面我们详细分析一下整体流程图中的实现。
KafkaConsumer.poll()
我们首先看一下消息发送入口的方法实现:
/**
* 从服务端获取消息
*/
public ConsumerRecords<K, V> poll(final Duration timeout) {
return poll(time.timer(timeout), true);
}
private ConsumerRecords<K, V> poll(final Timer timer, final boolean includeMetadataInTimeout) {
// 确保消费者未关闭
acquireAndEnsureOpen();
try {
if (this.subscriptions.hasNoSubscriptionOrUserAssignment()) {
throw new IllegalStateException("Consumer is not subscribed to any topics or assigned any partitions");
}
// 拉取消息直到超时
do {
client.maybeTriggerWakeup();
if (includeMetadataInTimeout) {
if (!updateAssignmentMetadataIfNeeded(timer)) {
return ConsumerRecords.empty();
}
} else {
/** 循环直到更新 metadata */
while (!updateAssignmentMetadataIfNeeded(time.timer(Long.MAX_VALUE))) {
log.warn("Still waiting for metadata");
}
}
/** 客户端拉取消息的核心逻辑 */
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = pollForFetches(timer);
if (!records.isEmpty()) {
/** 在返回数据之前, 发送下次的 fetch 请求, 避免用户在下次获取数据时线程阻塞 */
if (fetcher.sendFetches() > 0 || client.hasPendingRequests()) {
// 如果sendFetches() 数据到缓冲区或有unsent有数据, 则执行poll() 执行网络IO
client.pollNoWakeup();
}
return this.interceptors.onConsume(new ConsumerRecords<>(records));
}
} while (timer.notExpired());
return ConsumerRecords.empty();
} finally {
release();
}
}KafkaConsumer.poll() 方法中首先会调用 updateAssignmentMetadataIfNeeded() 更新metadata元数据信息,保证消费者正确的加入group。然后就是发送拉取的请求 pollForFetches(),下面我们详细的看一下 pollForFetches() 的实现。
pollForFetches()
/** 一次拉取过程, 除了获取新数据外, 还会做一些必要的 offset commit 和 offset reset 的操作 */
private Map<TopicPartition, List<ConsumerRecord<K, V>>> pollForFetches(Timer timer) {
long pollTimeout = coordinator == null ? timer.remainingMs() : Math.min(coordinator.timeToNextPoll(timer.currentTimeMs()), timer.remainingMs());
// 如果数据已经获取到了, 则立即返回
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = fetcher.fetchedRecords();
if (!records.isEmpty()) {
return records;
}
/** 外层循环会不断循环调用 pollForFetches(), 在返回给调用者之前, 会再次调用 sendFetches() + client.poll() 发起第二个网络请求 */
fetcher.sendFetches();
if (!cachedSubscriptionHashAllFetchPositions && pollTimeout > retryBackoffMs) {
pollTimeout = retryBackoffMs;
}
/** 执行真正的网络请求 */
Timer pollTimer = time.timer(pollTimeout);
client.poll(pollTimer, () -> {
/** 有完成的 fetcher 请求的话, 这里就不会阻塞; 阻塞的话也有超时时间 */
return !fetcher.hasCompletedFetches();
});
timer.update(pollTimer.currentTimeMs());
/** 如果 group 需要 rebalance, 直接返回空数据, 这样可以更快的让 group 进入稳定状态 */
if (coordinator != null && coordinator.rejoinNeededOrPending()) {
return Collections.emptyMap();
}
return fetcher.fetchedRecords();
}对于消息拉取的详细流程,上面代码中已经有注释描述。下面我们总结一下消息拉取时,上面代码做的一些优化操作。首先对于消息的拉取和处理主要流程如下所示:

对于KafkaConsumer.poll() 不断的去拉取消息的场景,此时如果两次拉取是串行的,这个时候可能就没有充分的利用KafkaConsumer 客户端的能力。因此我们从上面的代码中可以看出,在调用完 fetcher.fetchedRecords() 获取到结果之后,会异步的再去发起请求(fetcher.sendFetches())和轮询(client.poll()),以供下次拉取立即返回结果。
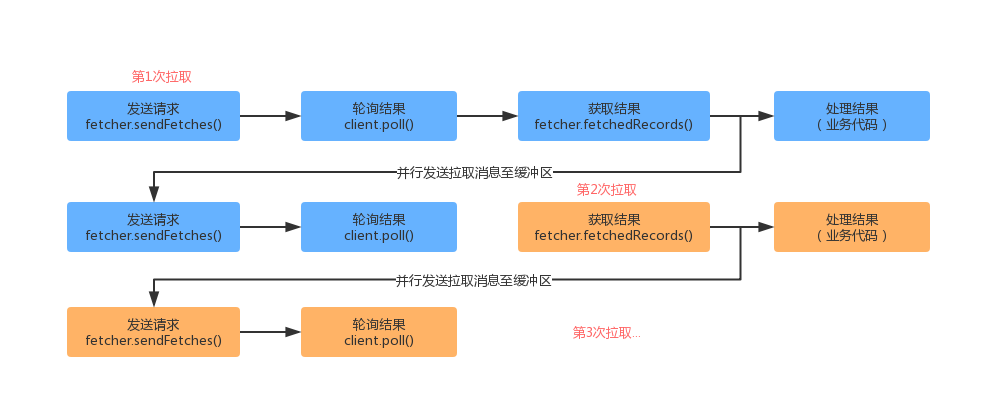
下面我们详细对发送请求(fetcher.sendFetches())、获取结果(fetcher.fetchedRecords())做详细介绍。
发送请求 Fetcher.sendFetches()
消费者 Fetcher 组件发送拉取请求的时候,也是和生产这类似,按照 Broker 的维度去发送请求。对于订阅的分区所属的节点信息,是存储在metadata 元数据信息里面的;对于消费者分区的消费位移 offset 是存储在订阅状态(SubscriptionState)中的。具体可用下面的流程图展示:
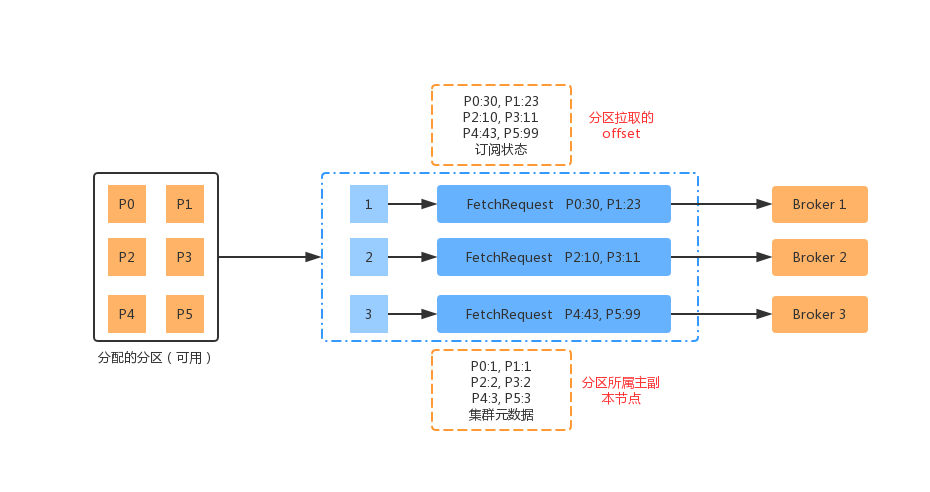
简单的描述一下上面的流程图:
(1)消费者向协调者申请加入 group,并得到分配给它的分区信息。
(2)集群元数据记录了分区及所属主副本节点的信息。
(3)消费者订阅状态记录了分区最近的拉取偏移量 offset 信息。
(4)Fetcher 发送请求时,会将所有分区按照Broker(主副本)的维度进行整理组装 FetchRequest。
(5)每个主副本对应一个FetchRequest,然后Fetcher 向Broker 发送请求。
下面我们看下具体的代码实现:
/**
* 如果一个 node 已经分配分区, 并且没有处理中的 Fetch 数据, 此时可以创建 FetchRequest 发送
* @return 发送了多少个 fetches 请求
*/
public synchronized int sendFetches() {
// Update metrics in case there was an assignment change
sensors.maybeUpdateAssignment(subscriptions);
// 按照 Node 的维度,构造 FetchRequest 请求
Map<Node, FetchSessionHandler.FetchRequestData> fetchRequestMap = prepareFetchRequests();
for (Map.Entry<Node, FetchSessionHandler.FetchRequestData> entry : fetchRequestMap.entrySet()) {
final Node fetchTarget = entry.getKey();
final FetchSessionHandler.FetchRequestData data = entry.getValue();
// 构建请求
final FetchRequest.Builder request = FetchRequest.Builder.forConsumer(this.maxWaitMs, this.minBytes, data.toSend())
.isolationLevel(isolationLevel).setMaxBytes(this.maxBytes).metadata(data.metadata()).toForget(data.toForget()).rackId(clientRackId);
if (log.isDebugEnabled()) {
log.debug("Sending {} {} to broker {}", isolationLevel, data.toString(), fetchTarget);
}
// 发送请求
client.send(fetchTarget, request).addListener(new RequestFutureListener<ClientResponse>() {
@Override
public void onSuccess(ClientResponse resp) {
synchronized (Fetcher.this) {
try {
@SuppressWarnings("unchecked")
FetchResponse<Records> response = (FetchResponse<Records>) resp.responseBody();
FetchSessionHandler handler = sessionHandler(fetchTarget.id());
if (handler == null) {
log.error("Unable to find FetchSessionHandler for node {}. Ignoring fetch response.", fetchTarget.id());
return;
}
if (!handler.handleResponse(response)) {
return;
}
Set<TopicPartition> partitions = new HashSet<>(response.responseData().keySet());
FetchResponseMetricAggregator metricAggregator = new FetchResponseMetricAggregator(sensors, partitions);
/** 遍历所有响应中的数据 */
for (Map.Entry<TopicPartition, FetchResponse.PartitionData<Records>> entry : response.responseData().entrySet()) {
TopicPartition partition = entry.getKey();
FetchRequest.PartitionData requestData = data.sessionPartitions().get(partition);
if (requestData == null) {
String message;
if (data.metadata().isFull()) {
message = MessageFormatter.arrayFormat("Response for missing full request partition: partition={}; metadata={}", new Object[]{partition, data.metadata()}).getMessage();
} else {
message = MessageFormatter.arrayFormat("Response for missing session request partition: partition={}; metadata={}; toSend={}; toForget={}", new Object[]{partition, data.metadata(), data.toSend(), data.toForget()}).getMessage();
}
// Received fetch response for missing session partition
throw new IllegalStateException(message);
} else {
long fetchOffset = requestData.fetchOffset;
FetchResponse.PartitionData<Records> fetchData = entry.getValue();
/** 创建 CompletedFetch, 并缓存到completedFetches 队列中 */
log.debug("Fetch {} at offset {} for partition {} returned fetch data {}", isolationLevel, fetchOffset, partition, fetchData);
completedFetches.add(new CompletedFetch(partition, fetchOffset, fetchData, metricAggregator, resp.requestHeader().apiVersion()));
}
}
sensors.fetchLatency.record(resp.requestLatencyMs());
} finally {
// 从发送中队列中移除
nodesWithPendingFetchRequests.remove(fetchTarget.id());
}
}
}
@Override
public void onFailure(RuntimeException e) {
synchronized (Fetcher.this) {
try {
FetchSessionHandler handler = sessionHandler(fetchTarget.id());
if (handler != null) {
handler.handleError(e);
}
} finally {
// 从发送中队列中移除
nodesWithPendingFetchRequests.remove(fetchTarget.id());
}
}
}
});
/** 加入发送中队列 */
this.nodesWithPendingFetchRequests.add(entry.getKey().id());
}
return fetchRequestMap.size();
}获取结果 Fetcher.fetchedRecords()
Fetcher 组件获取结果可能会直接利用上一次 KafkaConsumer.poll() 的 FetchRequest发送。此时如果我们假设 KafkaConsumer 订阅了 P0、P1、P2 三个分区,每次client.poll() 轮询会拿到4条消息,而一次fetch() 操作最多只可以获取2条消息(max.poll.records 设置的阀值)。此时可能会有如下流程:
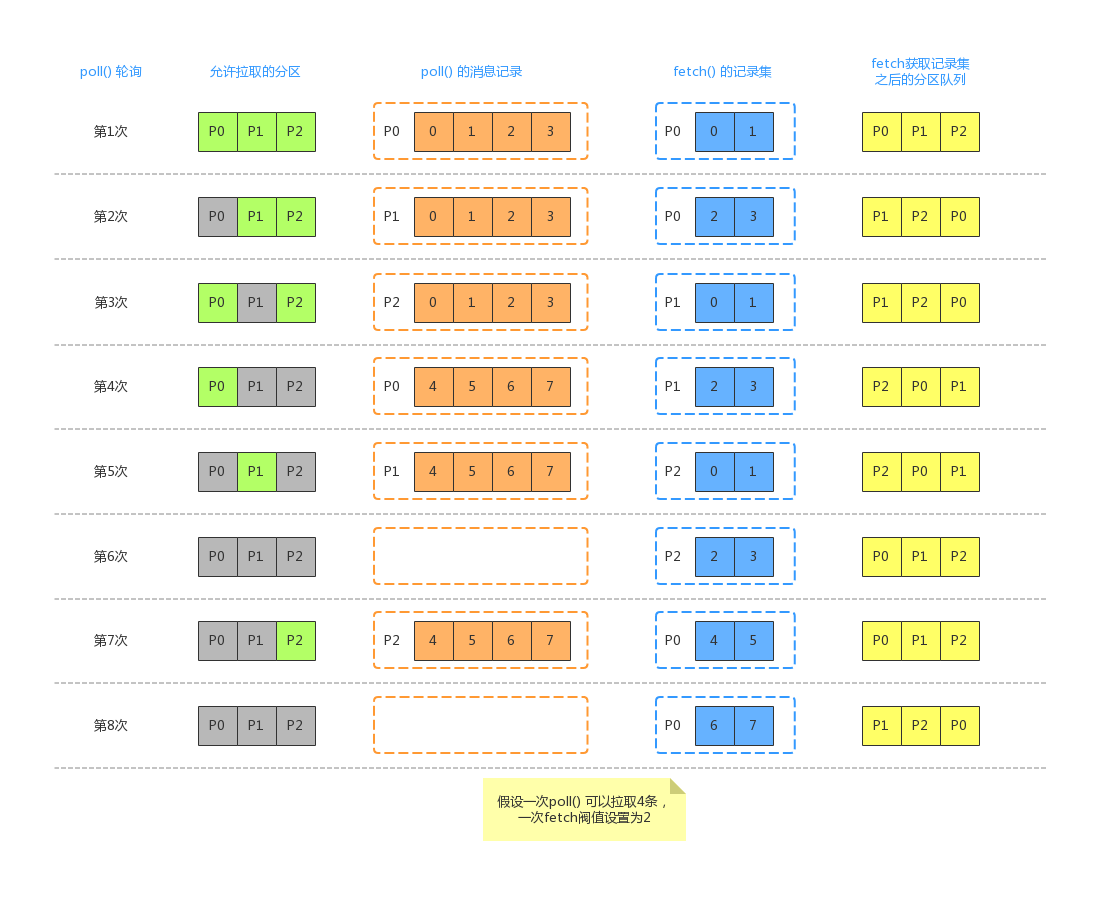
1、第一次调用 KafkaConsumer.poll() 获取消息时,允许拉取的分区是 P0、P1、P2(因为如果分区有未处理完成的记录,则不允许从服务端拉取,此时3个分区都没有未处理的消息在缓存中)。此时假设 Broker 端返回了 P0 的 0、1、2、3 四条消息,并存放在 P0 对应的缓存当中,同时返回的结果集只能给出 2 条,也就是 P0 的 0、1 。此时分区队列中的顺序还是 P0->P1->P2,因为P0 中的消息尚未处理完成,下一次 KafkaConsumer.poll() 还会继续从 P0 分区缓存中获取消息。
2、第二次调用 KafkaConsumer.poll() 获取消息时,允许拉取的分区是 P1、P2(此时P0尚有未处理完成的消息)。此时假设 Broker 返回了 P1 的 0、1、2、3 四条消息,并存放在 P1 对应的缓存中,但是此时给出的确是上面 P0 缓存中剩下的 2、3 两条消息。之后分区队列中的顺序变为 P1->P2->P0,下一次调用 KafkaConsumer.poll() 获取消息时,会首先从 P1 对应的缓存中获取数据。
3、第三次调用 KafkaConsumer.poll() 获取消息时,允许拉取的分区是 P0、P2(此时P0在缓存中的消息已经拉取完毕)。此时假设 Broker 返回了 P2的 0、1、2、3 四条消息,并存放在P2对应的缓存中,此时返回的是上一次结束分区队列头部的分区缓存中的数据,此时返回了 P1的0、1 两条消息。之后分区队列中的顺序不变,还是 P1->P2->P0,因为此时P1 缓存尚有数据。
4、第四次调用KafkaConsumer.poll() 获取消息时,只有P0 分区可以被拉取。此时假设 Broker 返回了 P0 的4、5、6、7 四条消息,并存放在P0对应的缓存中,此时返回了P1 的 2、3 两条消息,分区队列变为P2->P0->P1。
5、第五次调用KafkaConsumer.poll() 获取消息时,因为P1 缓存中的数据处理完了,此时只有P1 可被拉取。此时假设 Broker 返回了 P1 的 4、5、6、7 四条消息,并存放到P1对应的缓存中,此时返回了P2 的0、1 两条消息,分区队列依然为P2->P0->P1。
6、第六次调用KafkaConsumer.poll() 获取消息时,此时P0、P1、P2 分区对应的缓存中都有数据,此时没有分区可被拉取。此时直接返回P2 的2、3 两条消息。分区队列变为 P0->P1->P2。
7、第七次调用KafkaConsumer.poll() 获取消息时,此时只有P2 可以被拉取。此时假设 Broker 返回了 P2的 4、5、6、7 四条消息,并存放到 P2 对应的缓存中。此时返回了P0 的4、5 两条消息,分区队列依然为 P0->P1->P2。
8、第八次调用KafkaConsumer.poll() 获取消息时,此时无分区可被拉取。此时返回P0 的6、7 两条消息。分区队列变为P1->P2->P0。
下面我们看一下详细的代码实现:
/**
* 拉取数据(poll())完成后, 存储在 completedFetches 缓存中的数据尚未解析. 此时调用 fetchedRecords() 解析并返回
* @return 按照分区维度的消息记录
*/
public Map<TopicPartition, List<ConsumerRecord<K, V>>> fetchedRecords() {
Map<TopicPartition, List<ConsumerRecord<K, V>>> fetched = new HashMap<>();
int recordsRemaining = maxPollRecords;
try {
while (recordsRemaining > 0) {
if (nextInLineRecords == null || nextInLineRecords.isFetched) {
/** 上一个分区缓存中数据已处理完,则从分区队列中获取下一个分区缓存数据 */
CompletedFetch completedFetch = completedFetches.peek();
if (completedFetch == null) break;
try {
/** 解析分区缓存数据 CompletedFetch, 得到一个 PartitionRecords */
nextInLineRecords = parseCompletedFetch(completedFetch);
} catch (Exception e) {
FetchResponse.PartitionData partition = completedFetch.partitionData;
if (fetched.isEmpty() && (partition.records == null || partition.records.sizeInBytes() == 0)) {
completedFetches.poll();
}
throw e;
}
completedFetches.poll();
} else {
// 从分区缓存中获取指定条数的消息
List<ConsumerRecord<K, V>> records = fetchRecords(nextInLineRecords, recordsRemaining);
TopicPartition partition = nextInLineRecords.partition;
if (!records.isEmpty()) {
List<ConsumerRecord<K, V>> currentRecords = fetched.get(partition);
if (currentRecords == null) {
fetched.put(partition, records);
} else {
// this case shouldn't usually happen because we only send one fetch at a time per partition,
// but it might conceivably happen in some rare cases (such as partition leader changes).
// we have to copy to a new list because the old one may be immutable
List<ConsumerRecord<K, V>> newRecords = new ArrayList<>(records.size() + currentRecords.size());
newRecords.addAll(currentRecords);
newRecords.addAll(records);
fetched.put(partition, newRecords);
}
recordsRemaining -= records.size();
}
}
}
} catch (KafkaException e) {
if (fetched.isEmpty())
throw e;
}
return fetched;
}参考:《Apache Kafka 源码剖析》、《Kafka技术内幕》、http://matt33.com/2017/11/11/consumer-pollonce/



