对于一条消息而言,首先需要在生产者生产出来,然后发送给Broker存储,最终由消费者拉取处理。对于Kafka的生产者端的代码,有新旧两个版本。新客户端采用Java编写,源码在 client 目录下面;老版本由Scala 编写(目前已标记为"废弃"),源码放在 core 目录下面。
发送消息Demo
对于生产者的消息生产,官方给出的 Demo 里面有同步和异步两种方式。
public class Producer extends Thread {
private final KafkaProducer<Integer, String> producer;
private final String topic;
private final Boolean isAsync;
public Producer(String topic, Boolean isAsync) {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, KafkaProperties.KAFKA_SERVER_URL + ":" + KafkaProperties.KAFKA_SERVER_PORT);
props.put(ProducerConfig.CLIENT_ID_CONFIG, "DemoProducer");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
producer = new KafkaProducer<>(props);
this.topic = topic;
this.isAsync = isAsync;
}
public void run() {
int messageNo = 1;
while (true) {
String messageStr = "Message_" + messageNo;
long startTime = System.currentTimeMillis();
if (isAsync) { // 异步发送
producer.send(new ProducerRecord<>(topic, messageNo, messageStr),
new DemoCallBack(startTime, messageNo, messageStr));
} else { 同步发送
try {
producer.send(new ProducerRecord<>(topic, messageNo, messageStr)).get();
System.out.println("Sent message: (" + messageNo + ", " + messageStr + ")");
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
++messageNo;
}
}
}
// 事件回调
class DemoCallBack implements Callback {
private final long startTime;
private final int key;
private final String message;
public DemoCallBack(long startTime, int key, String message) {
this.startTime = startTime;
this.key = key;
this.message = message;
}
public void onCompletion(RecordMetadata metadata, Exception exception) {
long elapsedTime = System.currentTimeMillis() - startTime;
if (metadata != null) {
System.out.println(
"message(" + key + ", " + message + ") sent to partition(" + metadata.partition() + "), " + "offset(" + metadata.offset() + ") in " + elapsedTime + " ms");
} else {
exception.printStackTrace();
}
}
}
上面的 Producer 是一个线程,上面的例子我们只需要创建一个 Producer 线程并启动即可。对于同步异步的处理,调用 KafkaProducer.send() 的时候,返回的结果是一个 Future 对象。当调用 Future.get() 的时候,会同步等待结果返回;如果不调用,则就是异步提交。
KafkaProducer 执行流程
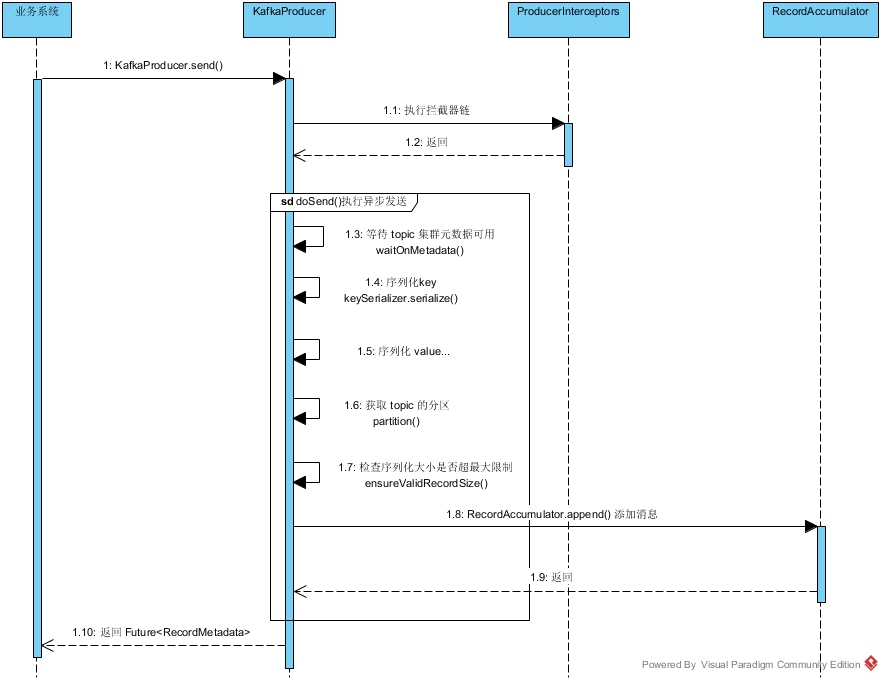
Kafka 生产者的大概执行流程如上图所示。当我们在业务系统中调用 KafkaProducer.send() 时,首先会进入执行 Producer 端的 拦截器链(在实际业务代码中,使用到拦截器的场景比较少)。执行完成之后,然后进入 doSend() 的异步发送流程。首先会等待对应 topic 的元数据可用,也就是检查 Cluster 中是否有对应的 topic ;然后分别对 key 和 value 序列化为 字节数组;之后再根据规则找到 topic 对应的分区,如果没有显示指定 topic 的分区,则使用默认的轮询策略或者如果指定了 key ,则按照 key 做 hash 分区;然后检查序列化的大小是否超过限制,如果满足限制,则调用 RecordAccumulator.append() 方法将消息追加到 RecordAccumulator 的管理队列里面去;最后返回一个 Future 类型的结果给业务代码。
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// 执行发送前的拦截器链
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
/**
* 异步发送消息执行.
*/
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
// 首先确保 topic 元数据信息可用, 也就是有分区可用
ClusterAndWaitTime clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs);
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
Cluster cluster = clusterAndWaitTime.cluster;
// 分别序列化 key value
byte[] serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
byte[] serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
// 计算出分区
int partition = partition(record, serializedKey, serializedValue, cluster);
TopicPartition tp = new TopicPartition(record.topic(), partition);
setReadOnly(record.headers());
Header[] headers = record.headers().toArray();
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(), compressionType, serializedKey, serializedValue, headers);
ensureValidRecordSize(serializedSize);
long timestamp = record.timestamp() == null ? time.milliseconds() : record.timestamp();
// 封装 callback, 以委派给 RecordAccumulator 处理后续流程
Callback interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, headers, interceptCallback, remainingWaitMs);
/** batch 队列中的大小 > 1 || 新 batch 已经满了 */
if (result.batchIsFull || result.newBatchCreated) {
this.sender.wakeup();
}
return result.future;
}为消息指定分区
对于一个 Topic 的消息而言,需要有一个唯一确定的分区来接收消息。在创建 KafkaProducer 的时候,我们可以在构造器中指定分区算法。自定义分区算法,需要实现 Partitioner 接口,并重写其中的 partition() 方法。如果我们没有显示的指定分区规则,那么默认会用 DefaultPartitioner 的实现,其分区方法如下:
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
// 1、如果没有指定 key, 则使用轮询策略, 均匀分布
if (keyBytes == null) {
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// 2、如果指定了 key, 则先对 key 做 Hash, 然后取模
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}从 Kafka 默认的分区规则看来,如果没有为消息指定 key,则使用轮询的策略;如果指定了 key,就按照 key 做 Hash,然后取模。
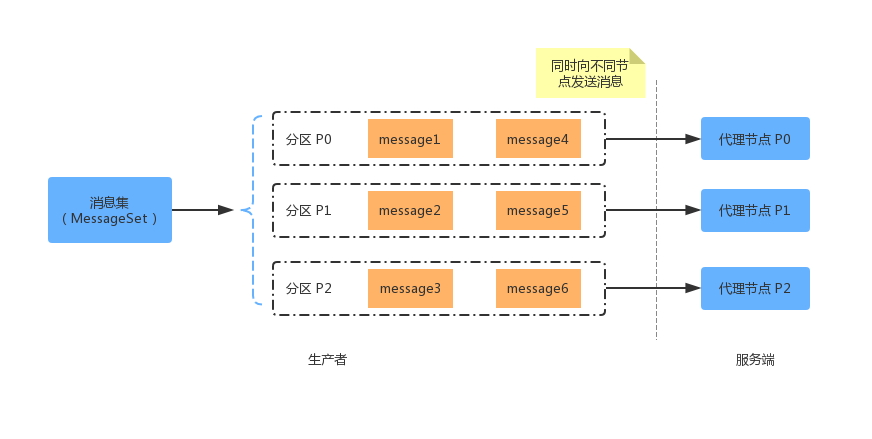
对于 Kafka 的默认消息分区策略,细心的读者可能注意到,在获取 Topic 分区列表的时候,获取的是可用分区列表。也就是说,如果此时为 Topic 为 tp1 的主题发送消息时(假设tp1 有 4 个分区,网络抖动前被分配到了 p3),如果此时第 4 个分区(p3)因为网络抖动不可用了,此时获取的可用分区就是 3 个。而我们对于指定 key 的消息,此时就打到了不同的分区。如果对消息的顺序性有要求的话,此时就可能造成消息的乱序。
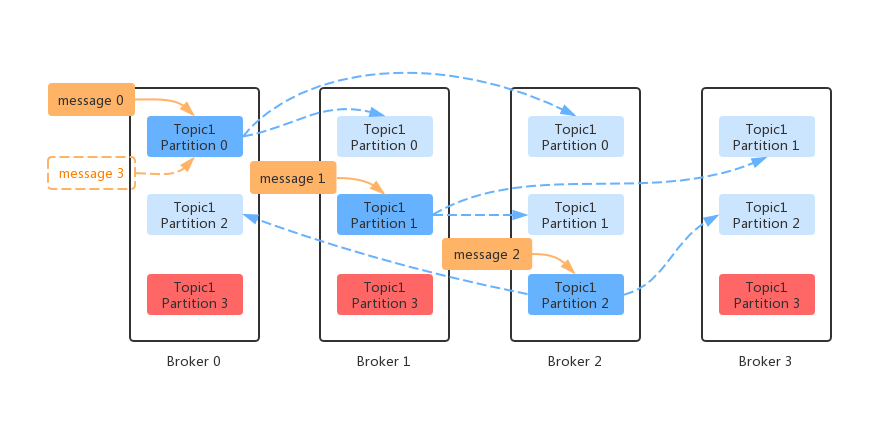
客户端记录收集器
从 KafkaProducer 的执行流程中我们可以看出,消息的存储最终委派给给了 RecordAccumulator。RecordAccumulator 是以 TopicPartition 的维度去批量存储待发送数据的。
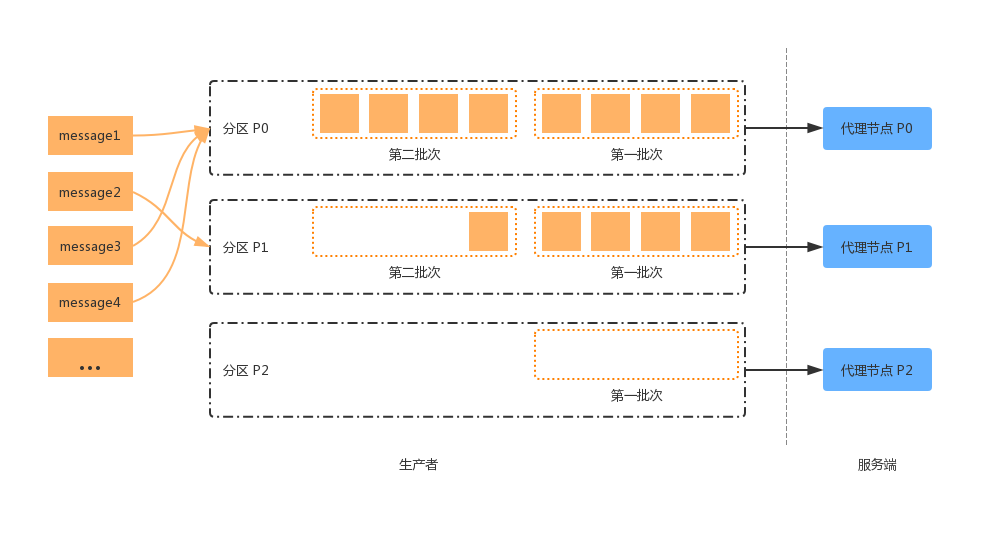
从上面可以看出,消息在 RecordAccumulator 中是以“批次”的形式管理的。当一个批次的消息满了之后,就可以准备被发送到 Broker 端了。
下面我们看一下,RecordAccumulator 的代码执行流程。
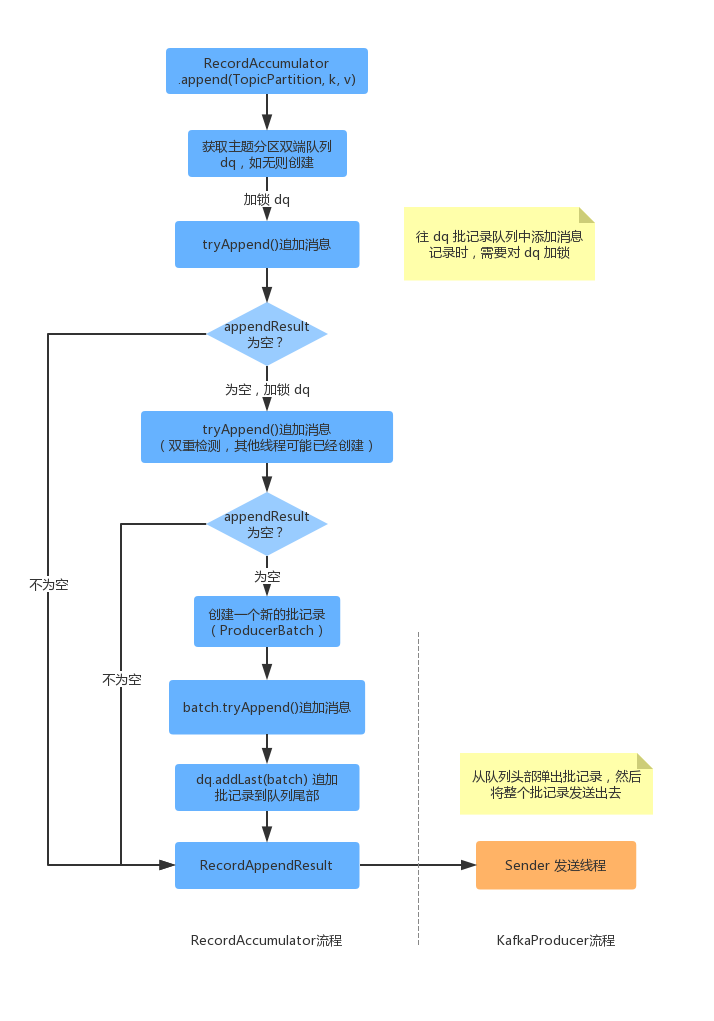
当我们调用完 RecordAccumulator.append() 方法的时候,首先会获取 topic 对应的 batch 队列,此时如果没有则会创建一个 topic 对应的队列 dq。然后对 dq 加锁,调用 tryAppend() 尝试追加消息,如果追加结果不为空则成功,如果为空则失败。此时说明当前 topic 对应的 batch 队列的最后一个 batch 已经满了,需要重新创建一个了。上面的流程有一点需要注意的是,对于 dq 的加锁并不是全局的,减小了加锁的粒度。此时再次对 dq 加锁之后,有个双重检测的过程,如果再次添加失败,则需要创建一个新的 batch,append 完消息之后,追加到 dq 的尾部。之后会返回 RecordAppendResult 的结果给到 KafkaProducer,然后判断 RecordAccumulator 管理的 batch 队列是否符合发送条件,如符合则委派 Sender 发送消息批次。
/**
* 添加消息到 accumulator, 并返回结果
*/
public RecordAppendResult append(TopicPartition tp, long timestamp, byte[] key, byte[] value, Header[] headers, Callback callback, long maxTimeToBlock) throws InterruptedException {
/** 记录并发调用的线程数 */
appendsInProgress.incrementAndGet();
ByteBuffer buffer = null;
if (headers == null) headers = Record.EMPTY_HEADERS;
try {
// 获取 tp 对应的 batch 队列
Deque<ProducerBatch> dq = getOrCreateDeque(tp);
synchronized (dq) {
if (closed)
throw new KafkaException("Producer closed while send in progress");
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null)
return appendResult;
}
// 追加失败(说明 queue 尾部的 batch 已满), 则申请空间 创建新的 batch
byte maxUsableMagic = apiVersions.maxUsableProduceMagic();
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));
log.trace("Allocating a new {} byte message buffer for topic {} partition {}", size, tp.topic(), tp.partition());
buffer = free.allocate(size, maxTimeToBlock);
synchronized (dq) {
if (closed)
throw new KafkaException("Producer closed while send in progress");
// 双重检测
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null) {
return appendResult;
}
// 创建新 batch, 添加消息
MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic);
ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, time.milliseconds());
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, headers, callback, time.milliseconds()));
dq.addLast(batch);
incomplete.add(batch);
// Don't deallocate this buffer in the finally block as it's being used in the record batch
buffer = null;
return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true);
}
} finally {
if (buffer != null)
free.deallocate(buffer);
appendsInProgress.decrementAndGet();
}
}消息发送时的整理
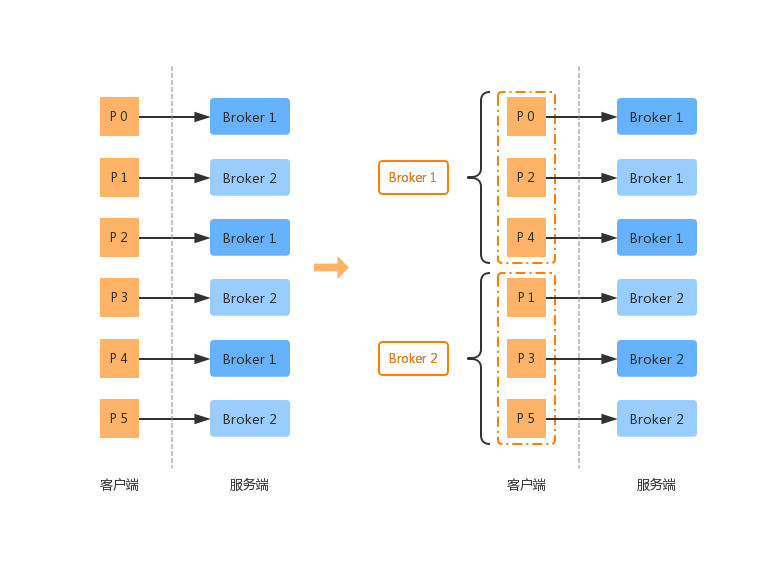
通过之前的描述,我们知道 RecordAccumulator 追加消息的维度是 TopicPartition。那么我们此时要发送给对应的 Broker 的时候,应该要怎样处理呢?是不是还是需要按照 TopicPartition 的维度呢?
当然按照 TopicPartition 的维度发送也没有关系,但是更高效率的是我们可以按照 Broker 的维度去发送 batchs。因此在 KafkaProducer 发现批次满足发送条件,委派 Sender 发送时,会重新整合 batchs 的维度,以减少网络开销。
参考:《Kafka技术内幕》、《Apache Kafka源码剖析》、Kafka源码



