分区模型
之前我们提到,Kafka 里面同一个 Topic 下面的消息,会存放在多个分区上面。每条消息在添加到分区时,都会被分配一个 offset,它是消息在此分区中的唯一编号。Kafka 通过 offset 保证消息在分区内的顺序,在多个分区之间并不保证消息是有序的。
Kafka 的分区能力,其实就是提供了消息负载均衡的能力。当消息存量的负载较高时,可以通过水平扩展来平滑压力。
分区策略
这里的分区策略,就是说生产者如何决定将一个消息发送到哪个分区上面去。对于Java 的客户端来说,确定分区的方法签名如下:
int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);

可以看出客户端提供了多种参数的原料,用来加工生成结果的分区ID。下面看一下常见的分区策略。
轮询策略
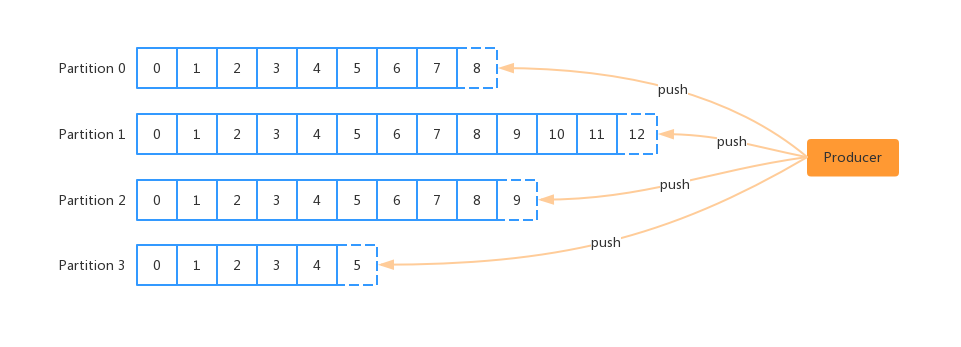
轮询策略(Round-robin),顾名思义就是在每个 Partition 上面平均的分配 Topic 下面的消息,如下图所示:
轮询策略可以做到严格意义上的平均,默认情况下也是最合理的分区策略。
随机策略
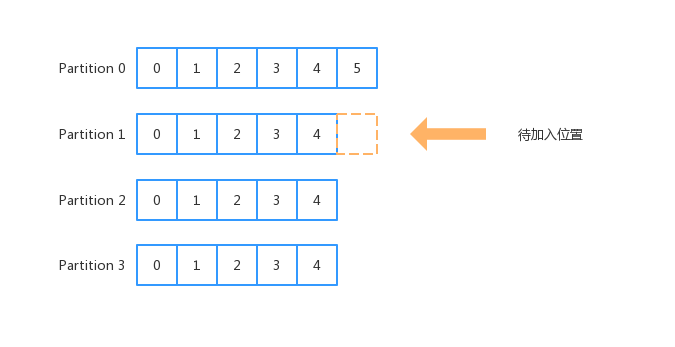
随机策略(Randomness),也就是生产出来一条消息后,随机的分发到一个 Partition 上面。在数据较多时,从概率统计上面来说,最终各个分区的数据量会相差不大,但是并不是严格均等的。
从总体上面,随机和轮询策略大致是相同的。但是在新版本的 Kafka 里面已经使用轮询来替代随机策略了。
key-ordering 策略
Kafka 可以为每条消息指定一个 key,这个 key 可以是 userId、productId 等等。如果一个消息指定了 key ,就可以将同样 key 的消息存放在同一个 Partition 里面,这就是 key-ordering 策略。如下所示:
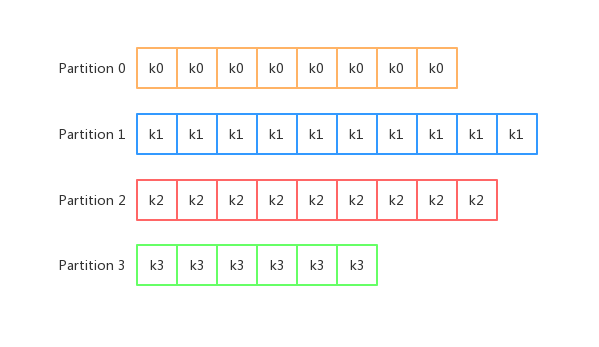
对于Kafka 默认的分区策略:如果没有指定 key,则按照轮询的方式指定 Partition;如果指定了 key,则以key-ordering 策略指定。
其他策略
在实际应用当中,可能会跨机房的 Kafka 集群,这个时候如果要针对不同机房的节点发送不同的消息。此时可能会需要按照 IP 的方式做分区了。
参考:《极客时间:Kafka核心技术与实战》、《Kafka源码剖析》



