对于MySQL 的加锁规则,笔者之前了解到的也只是行锁的概念。除了业务代码中使用的乐观锁、悲观锁,也没有深入了解MySQL 真正加锁规则。也不知道MySQL 在可重复读隔离级别下,为什么可能会出现幻读。今天的这篇文章来详细描述一下其原理。(本文所有Demo都基于可重复读隔离级别)
首先我们来创建一张表,并写入几条语句。
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB;
insert into t values(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);
解决幻读
我们知道的是,在执行更新语句的时候,MySQL 会加行锁。但是仅仅加行锁的话,可能是锁不住的(因为此时记录中可能不存在被锁的行),此时MySQL 里面还有一个 间隙锁(Gap Lock)的概念。上面的建表语句会形成如下图所示的间隙:

当我们执行如下SQL 语句时,就不止给已经存在的6 条记录加行锁,还要给 7 个间隙加锁(因为 d 字段没有索引,SQL 中被扫描到的行都会加锁,因此是所有记录都会加锁)。这样就保证了无法再写入 d=5 的记录了,从而保证了SQL 的语义正确。
mysql> select * from t where d = 5 for update;对于行锁来讲,我们知道读锁和写锁的互斥关系如下。而对于间隙锁来讲,两个间隙锁之间并不互斥,互斥的是间隙锁和往间隙里面插入记录的操作。
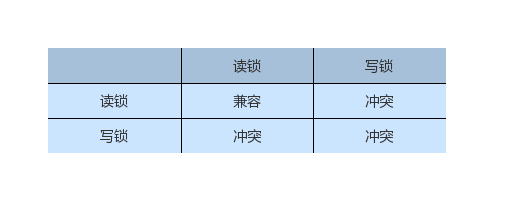
比如我们执行如下的SQL,然后会发现后面执行的语句并不会被 Blocked。Session A 加的间隙锁是 (5,10),当Session B再加间隙锁时,也是可以加上的。它们功能的目标就是保护这个间隙不被写入数据,它们之间并不冲突。

间隙锁和行锁被统称为 next-key lock,每个 next-key lock 都是一个前开后闭的区间。如上面的 Demo 就会有 7 个next-key lock:(-∞, 0]、(0, 5]、(5, 10]、(10, 15]、(15, 20]、(20, 25]、(25, +supremum]。间隙锁解决了一些问题,但同时也带来了其他的一些问题。

当 Session A 和 Session B 同时执行相同的事务处理时,可能会造成 B 的 insert 被A 的间隙锁 (5,10) 挡住,A 的 insert 被 B 的间隙锁 (5,10) 挡住,从而造成了死锁。由此看来,间隙锁造成了更大程度上面的锁,从而会影响系统的并发度。
加锁规则
1、原则1:加锁的基本单位是 next-key lock (前开后闭)。
2、原则2:查找过程中访问到的对象才会被加锁。
3、优化1:唯一索引上的等值查询,next-key lock 会退化为行锁。
4、优化2:普通索引上的等值查询,向右遍历最后一个不满足等值条件时,next-key lock 会退化为间隙锁。
5、一个 bug:唯一索引上的范围查询,会访问到不满足条件的第一个值为止。
Demo1:等值查询间隙锁
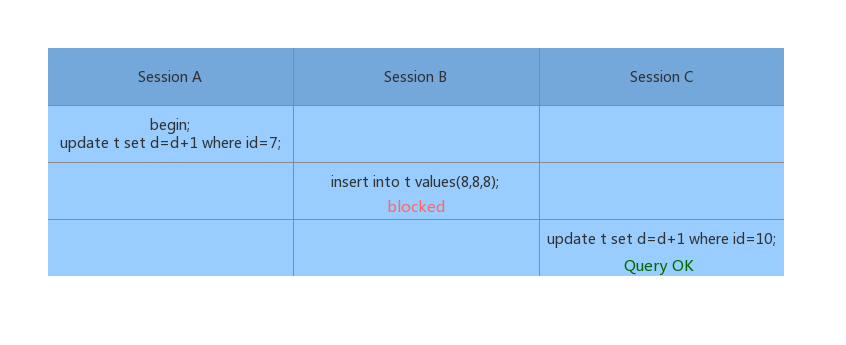
因为 表 t 中没有 id=7 的记录,1、根据原则1 Session A 的加锁范围就是 next-key lock (5, 10];2、根据优化2,id=10 不满足条件,next-key 会退化为间隙锁, Session A 最终的加锁范围就是 (5, 10)。所以 Session B 写入 id=8 的记录会被锁住,而 Session C 对 id=10 的更新会执行成功。
Demo2:非唯一索引等值锁
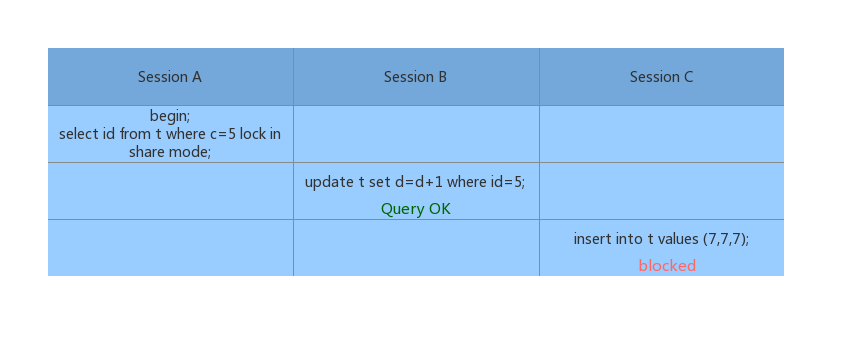
这里感觉是不是很怪,觉得 Session B 也应该被锁住。(注意一下 Session A 里面是对 c = 5加了锁)
1、根据原则1,next-key lock 是(5, 10];2、c 是普通索引,扫描到 c=5 时需要继续往后扫描,next-key lock 是(5, 10],因为是等值查询,根据优化 2 此时会退化为间隙锁 (5, 10);3、根据原则 2,只有访问到的对象才会被加锁,因为 Session A 使用到了覆盖索引(只访问了 id),因此主键上面并没有加锁。这就是为什么 Session B 为什么会成功,而 Session C 被 (5, 10) 的间隙锁锁住了。
在这个Demo 中还有一个需要注意的是,Session A 里面使用的是 lock in share mode,它只锁覆盖索引。如果使用的是 for update,则满足条件的主键也会被加锁。
Demo3:主键索引范围锁
看Demo 之前我们先看一下下面 2 条语句的加锁过程,从逻辑上看是相同的,但是加锁过程它们是不同的。
mysql> select * from t where id=10 for update;
mysql> select * from t where id>=10 and id<11 for update;
1、Session A 开始执行时,next-key lock 是 (5, 10],查询在 (5, 10] 段是等值查询,因此退化为行锁;2、后续的范围查询,next-key lock 是 (10, 15]。因此最终的加锁是 id=10 的行锁和 (10, 15] 的next-key lock。这里面可能会看着有些怪,范围查询不是不优化的么?这里面需要注意的是,是范围查询还是等值查询,也需要先按区间段去切割一下。
Demo4:非唯一索引范围锁
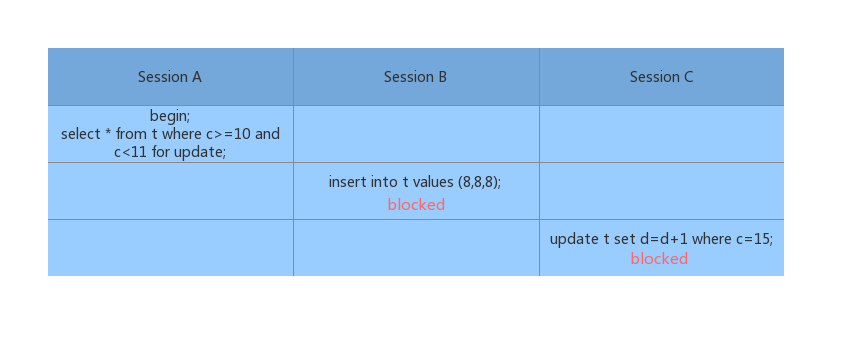
1、对于 Session A,首先有(5, 10] 的next-key lock ,但是最后一个 c = 10 满足条件,因此不会走 优化2,还是(5, 10] 的next-key lock;2、在(10, 15] 上面是范围查询,因此还是 (10, 15] 的next-key lock。最后Session A 的加锁就是 (5, 10] 和 (10, 15] 的 next-key lock。
Demo5:唯一索引范围锁bug
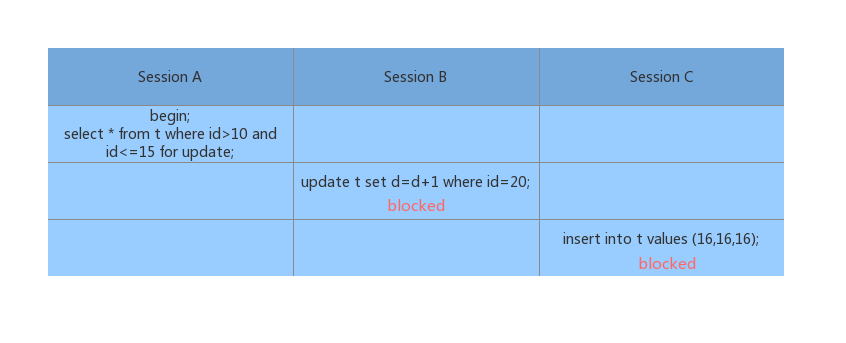
1、对于 Session A 来说,会有(10, 15] 的 next-key lock,但是对于唯一索引来说应该不会继续往后查询了,但是还会继续;2、其还会在(15, 20] 上面加上 next-key lock。因此出现了上图的结果。
Demo6:非唯一索引上存在“等值”的例子
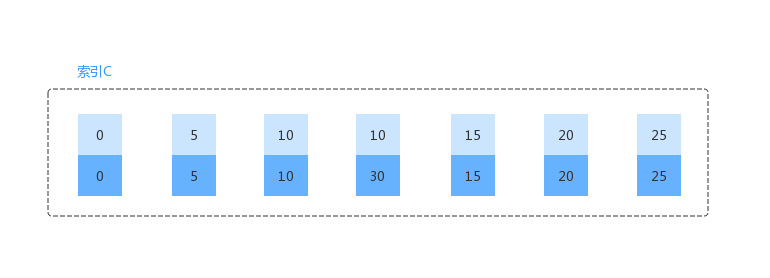
在最上面给出的基础数据之上,再增加下面的一条数据。
mysql> insert into t values(30,10,30);写入之后,对于索引 c 来讲有如下结构。可以看出数据之间的间隙又增加了。
对于 delete 语句,其执行加锁的规则和 select ... for update 是类似的。
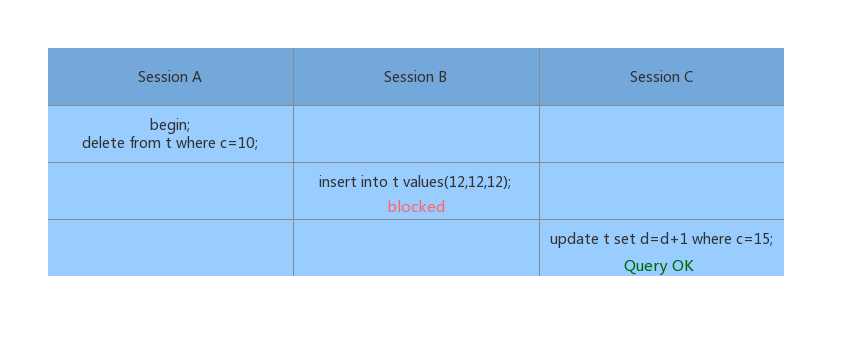
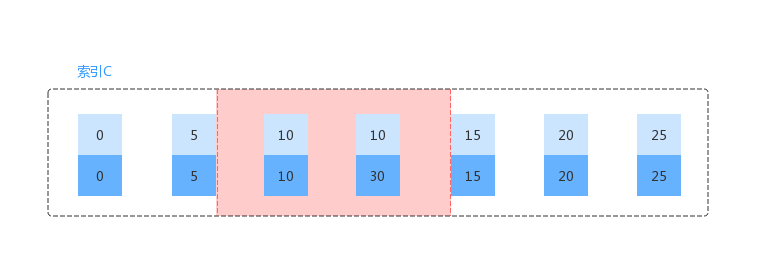
1、Session A 开始,会有一个 ( (c=5,id=5), (c=10,id=10) ] 的 next-key lock,因为最后一个值满足条件,因此不会退化;2、一直向后遍历到 (c=15,id=15) 时,该值不满足条件,因此 ( (c=10,id=30), (c=15,id=15) ] 的 next-key lock 会退化为间隙锁;最终结果如下图所示:
Demo7:limit语句加锁

1、Session A 和上一个Demo 不同的是,增加了 limit 2 这个操作,其实扫描到 (c=10,id=30) 这个记录时,就已经停止了。因此最后的加锁范围如下所示:
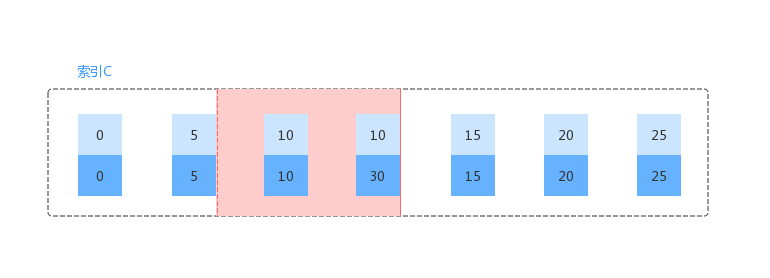
从上面 limit 的例子我们可以看出,在写SQL的时候,能加限制的就尽量加一下,以减少MySQL 的加锁范围。
Demo8:一个死锁的例子
前面我们说的 next-key lock 是一个整体的概念,但是实际加锁过程中,next-key lock 还是由 间隙锁 和 行锁分开执行加锁的。

1、首先 Session A 加了 (5, 10] 的 next-key lock 和 (10, 15) 的间隙锁;2、Session B也要在 (5, 10] 上面加上 next-key lock 而进入锁等待;3、Session的 insert 被 Session B 的间隙锁锁住,从而出现了死锁现象。
由此可以看出来,next-key lock 是由 2 部分组成的: (5, 10)的间隙锁 和 10 的行锁。
参考:《极客时间:MySQL实战》、《高性能MySQL》



