在互联网应用中,通常情况下我们查询DB 只会使用简单的、查询效率较高的SQL,大部分的逻辑都需要在代码中去实现。今天介绍一下,一些看起来简单的SQL,也有可能导致查询性能的低下。
WHERE条件字段使用函数
假设我们有如下创建表的语句
mysql> CREATE TABLE `tradelog` (
`id` int(11) NOT NULL,
`tradeid` varchar(32) DEFAULT NULL,
`operator` int(11) DEFAULT NULL,
`t_modified` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `tradeid` (`tradeid`),
KEY `t_modified` (`t_modified`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
上面是一种时间维度的业务表,此时如果我们要仅仅查询所有数据中 7月份的交易笔数。此时我们可能会想到如下SQL
mysql> select count(*) from tradelog where month(t_modified)=7;从上面的建表语句我们可以看出,索引是建在 t_modified 上面的。此时如果我们要查询上面的SQL 查询,执行过程将会是如下:
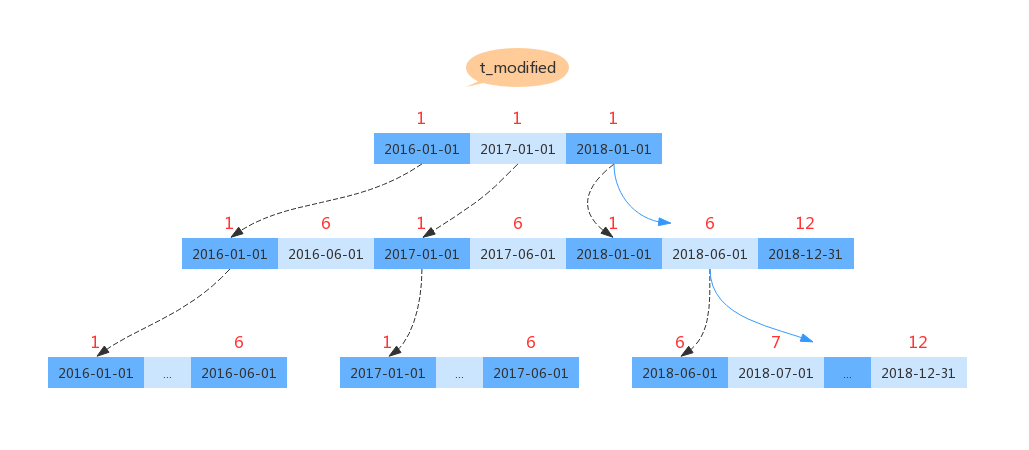
从上图可以看出,当对索引字段做函数操作后,可能会造成索引结构顺序的错乱。因此,MySQL 会放弃走搜索树的查询结构,取而代之的是全索引扫描。(优化器选择走 t_modified 索引全表遍历,而不选择 主键索引的原因是 t_modified 索引相对小一点)
通常情况下,我们需要人工的去优化SQL 。当然这往往需要结合具体的业务数据去处理了,如上面的查询可能会优化为如下的情况:
select count(*) from tradelog where (t_modified >= '2016-7-1' and t_modified < '2016-8-1') or
(t_modified >= '2017-7-1' and t_modified < '2017-8-1') or
(t_modified >= '2018-7-1' and t_modified < '2018-8-1');对于MySQL 的简单查询来说,还有一个坑就是:
SELECT * FROM tradelog WHERE id + 1 = 999; 这个时候,MySQL 也不会主动的去做 “移项”的优化,此时也会造成全表扫描。
字段隐式转换
MySQL 中的字段隐式转换可能会引起索引不可用,下面我们先看一个字符与数字比较的例子。如下所示:
mysql> select '10' > 9;当我们执行上面的SQL 时,会得到如下结果

从执行结果可以看出,字符类型默认会转换为数字类型。需要注意的点是:'10' ->10、'10A' -> 10、但是 'A10' -> 0 ,转换会过滤掉无效字符,但是需要数字开头,否则就转化为 0 。
现在我们看一下如下语句:
mysql> explain select * from tradelog where tradeid = 222;
因为 tradeid 是 VARCHAR 类型,MySQL 会将其转化为 数字然后比较,最终导致索引不可用,全表扫描。当我们对 int 类型字段查询时,对应的value 值可以随意使用 10 或者 '10' ,此时都会转化为 数字 10 ,使用索引。上面的语句执行就相当于如下:
mysql> explain select * from tradelog where CAST(tradeid AS signed int) = 222;也就是隐藏的在查询字段上面使用了函数操作,从而导致了全表扫描。
隐式字符编码转换
上面的案例介绍了,不同类型字段之间的类型转换。对于相同类型(VARCHAR) 的不同字符集编码也可能会出现隐式转换。下面再创建一张日志详情表(trade_detail),然后在写入一些数据,如下所示:
mysql> CREATE TABLE `trade_detail` (
`id` int(11) NOT NULL,
`tradeid` varchar(32) DEFAULT NULL,
`trade_step` int(11) DEFAULT NULL, /* 操作步骤 */
`step_info` varchar(32) DEFAULT NULL, /* 步骤信息 */
PRIMARY KEY (`id`),
KEY `tradeid` (`tradeid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into tradelog values(1, 'aaaaaaaa', 1000, now());
insert into tradelog values(2, 'aaaaaaab', 1000, now());
insert into tradelog values(3, 'aaaaaaac', 1000, now());
insert into trade_detail values(1, 'aaaaaaaa', 1, 'add');
insert into trade_detail values(2, 'aaaaaaaa', 2, 'update');
insert into trade_detail values(3, 'aaaaaaaa', 3, 'commit');
insert into trade_detail values(4, 'aaaaaaab', 1, 'add');
insert into trade_detail values(5, 'aaaaaaab', 2, 'update');
insert into trade_detail values(6, 'aaaaaaab', 3, 'update again');
insert into trade_detail values(7, 'aaaaaaab', 4, 'commit');
insert into trade_detail values(8, 'aaaaaaac', 1, 'add');
insert into trade_detail values(9, 'aaaaaaac', 2, 'update');
insert into trade_detail values(10, 'aaaaaaac', 3, 'update again');
insert into trade_detail values(11, 'aaaaaaac', 4, 'commit');当我们需要查询一条交易记录(trade_log) 中的全部交易详情(trade_detail) 时,可能会使用如下SQL
mysql> explain select d.* from tradelog l, trade_detail d where d.tradeid=l.tradeid and l.id=2;
上面第一行是对 trade_log 的 id = 2 的这一条记录执行的查询,使用了主键索引,扫描行数 1 ;但是第二条没有使用 trade_detail 上的 tradeid索引,是不是感到有些奇怪。
在上面的执行计划里面,先是从 trade_log 里面去查询 id=2 的记录,然后再去匹配 trade_detail 。这里面 trade_log 称为 驱动表,trade_detail 称为 被驱动表,其执行流程如下所示:
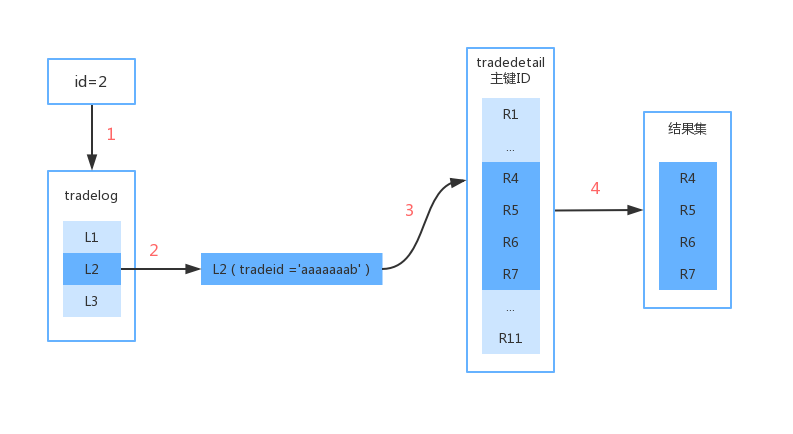
那么上面第二条执行计划为什么没有走索引呢,仔细看你会发现上面 2 张表创建时所使用的字符集编码不同,一个是 utf8 一个是 utf8mb4 。utfutf8mb4 是 utf8 字符集的超集,当我们将 两张表的字段进行比较时,utf8 会转换为utf8mb4 (避免精度丢失)。
上图中的第 3步可以认为是执行如下操作($L2.tradeid.value 是 utf8mb4 的字符值):
mysql> select * from trade_detail where tradeid = $L2.tradeid.value;隐式转换后的执行SQL 如下:
mysql> select * from trade_detail where CONVERT(tradeid USING utf8mb4)=$L2.tradeid.value;由此看来,执行的过程中对 trade_detail 的查询字段 tradeid 使用了函数,因此不走索引。但是当我们反过来查询时,也就是从一条 trade_detail 去关联对应的 trade_log 时,会是什么情况呢?
mysql> explain select l.operator from tradelog l, trade_detail d where d.tradeid=l.tradeid and d.id=4;
由上图可以看出,第二次查询使用到了 tradelog的 tradeid 索引了。当第一个执行计划找到 trade_detail 中 id=4 的记录后(R4),再去tradelog 中关联对应的记录时,执行的SQL 如下:
mysql> select operator from tradelog where traideid =$R4.tradeid.value;此时 等号右边的 value 值需要做隐式转换,并没有在索引字段上做函数操作,如下所示:
mysql> select operator from tradelog where traideid =CONVERT($R4.tradeid.value USING utf8mb4);解决方案
对于字符集不同造成的索引不可用,可以使用如下 2 中方式去解决。
1、修改表的字符集编码。
mysql> alter table trade_detail modify tradeid varchar(32) CHARACTER SET utf8mb4 default null;2、手工字符编码转换。
mysql> select d.* from tradelog l, trade_detail d where d.tradeid=CONVERT(l.tradeid USING utf8) and l.id=2;参考:《极客时间:MySQL实战》、《高性能MySQL》



