MySQL用了好多年了,但是对于大部分开发人员来说,还是停留在使用上面。接下来的数篇文章将记录一下,MySQL原理的实现原理。
首先看一下MySQL的架构图,如下所示:
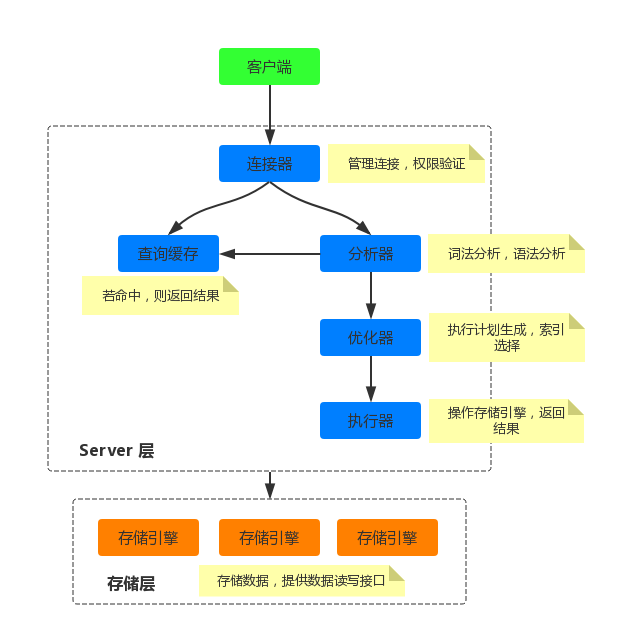
从上面的示意图可以看出,MySQL从上到下包含了:客户端、Server层和存储引擎层。对于客户端实现,可以是我们常用的MySQL命令行窗口,或者是Java的客户端程序等等,这里不做过多的介绍。
Server层主要包括了:连接器、查询缓存、分析器、优化器和执行器等。大部分MySQL对用户提供的功能,都在这一层实现:包括了内置函数的实现,存储过程、触发器、视图等等。
存储引擎层负责数据的存储和提取,存储引擎的实现是插件式的。也就是说用户可以选择自己所需要的存储引擎,如InnoDB、MyISAM等。
连接器
连接器是MySQL服务端对外的门户,当我们使用命令行黑窗口或者JDBC的Connection.connect(),连接到MySQL Server端时,会校验用户名和密码;然后会查询用户对应的权限列表。当连接建立后,后续的权限范围就在此时确定了,如果连接没有断开的情况下,更改了用户的权限,此时对于该连接也不生效。
当连接建立后,如果没有后续的操作,连接就会进入空闲状态。此时可以使用如下命令,查看当前的连接状态。
mysql> show processlist
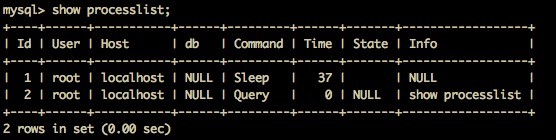
如果客户端连接太长时间没有使用,连接器就会将其断开。这个参数是由 wait_timeout 控制的,默认时间是8小时。从上面连接过程可以看出,MySQL客户端连接的建立过程还是比较耗时的。在我们开发的过程中,通常会使用长连接,但是如果过多的使用长连接,就会造成MySQL的内存占用量很大(MySQL5.7 以后,可以使用 mysql_reset_connection 来重新初始化连接资源,从而达到释放内存占用的目的)。
因此在实际开发中(以Java为例),会使用DBCP、C3P0或者Druid的连接池来管理连接。其中Druid是阿里巴巴开源的连接池管理工具,还具备监控相关的功能,功能比较强大,笔者比较推荐。
查询缓存
当连接建立完成后,执行select 语句的时候,就会来到查询缓存。MySQL会将Select 语句为 KEY,将查询结果为VALUE 的形式保存在内存中。如果匹配到对应的 KEY 就会直接从内存中返回结果。
但是通常我们不会使用MySQL自身的查询缓存,因为当有一条Update 或者 Insert 的改表语句时,就会清空对该表的所有查询缓存。缓存的粒度比较大,可以考虑类似 Redis 的分布式缓存做业务数据的缓存。在MySQL 8.0 中,查询缓存直接被移除了。
分析器
接着上面的,如果在查询缓存中没有查到数据,就要真正的开始执行SQL语句了。分析器首先会做“词法分析”,如:
mysql> select id, name from T where id = 1;词法分析就是识别上面字符串,id、name 是表的字段名,T 是表的名称等等。之后就是语法分析,如果SQL有语法错误,在此时就会报错。
优化器
当分析器处理过之后,MySQL就知道SQL 要干什么了,但是此时还需要优化器对待执行的SQL 进行优化。当然MySQL 提供的优化器,相比其他几款商用收费的数据库来说还是比较弱的。当然MySQL 的优化器还是可以对 join 操作,表达式计算等等进行优化,本篇不做过多的介绍。
执行器
执行阶段,首先会检查当前用户有没有权限操作该 SQL 语句。如果有,则继续执行后续的操作。
参考:《极客时间:MySQL实战》、《高性能MySQL》



