Apache Zookeeper是由Apache Hadoop的子项目发展而来的,在2010年11月正式成为了Apache的顶级项目。ZK为分布式应用提供了高效可靠的分布式协调服务,如:统一命名、配置管理、分布式锁、发布/订阅、负载均衡等。它采用的是一种名为ZAB(ZooKeeper Atomic Broadcast)的一致性协议。
ZK分布式一致性
顺序一致性:从同一个客户端发起的请求,最终会严格地按照其发起顺序被应用到ZK中去。
原子性:所有事务的处理结果在整个集群中所有机器上的应用情况是一致的。换句话说,要么整个集群都成功执行了一个事务,要么就全部都没执行。
单一视图:无论客户端连接的是哪一个ZK服务器,它看到的服务端模型都是一致的。
可靠性:一旦服务端成功的应用了一个事务,并且完成了对客户端的响应,那么它对服务端的变更是持久性的,直到下一个事务的执行。
实时性:这里需要注意的是,ZK仅仅保证在一定的时间段内,客户端最终一定能够从服务器上读取到最新的数据状态。
ZK的设计目标
简单的数据模型
ZK的数据模型是由一系列的ZNode(数据节点)组成的,可以类比为一个文件系统。不过与传统文件系统不同的是,ZK将全量数据存储在内存中,从而实现高吞吐、低延迟的目的。
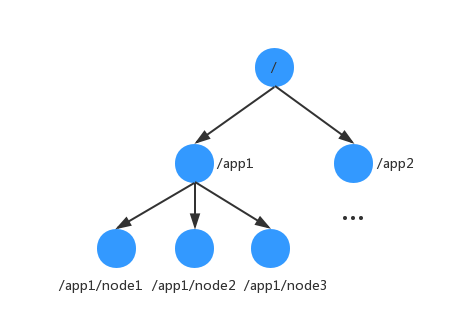
可以构建集群
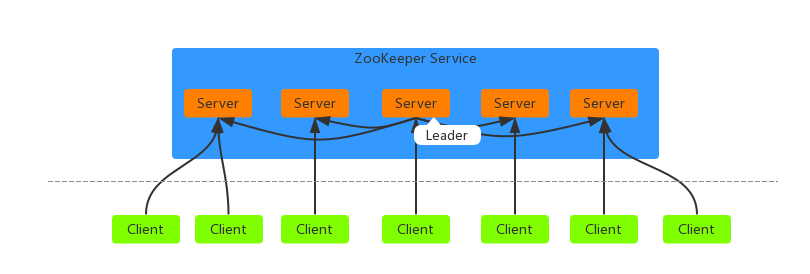
一个ZK集群由一组机器组成,一般由3~5台机器就可以组成一个可用的集群了。(建议奇数台机器)
顺序访问
对于客户端的每一个请求,ZK都会分配一个全局唯一的递增编号,这个编号反映了所有事务执行的先后顺序。
高性能
ZK将全量数据存储在内存中,并直接服务于客户端的所有非实物请求,因此它非常适合读多的场景。
基本概念
集群角色
ZK并没有沿用传统的Master/Slaver概念,其引入了Leader、Follower和Observer三种角色。
Leader:为客户端提供写和读服务(参与选举)
Follower:只提供读服务(参与选举)
Observer:只提供读服务(不参与选举)
会话
会话是指客户端和服务器之间的一条TCP长连接。ZK对外服务的端口默认是2181,客户端启动的时候,就会与服务端建立一条TCP长连接。两端可以通过心跳监测保持会话,还可以通过该长连接接收来自服务器的Watcher事件通知。
数据节点(ZNode)
ZK的数据节点分为两类:持久节点和临时节点。持久节点创建后不会因Session断开/失效而删除,而临时节点会随着会话的消失而删除。还可以为节点添加SEQUENTIAL属性,会在节点名称上面添加整型序列,序列由父节点维护。
版本
ZK会为每个ZNode维护一个叫做Stat的数据结构。其中记录了:version(当前ZNode的版本)、cversion(当前ZNode子节点的版本)和aversion(当前ZNode的ACL版本)。
Watcher
Watcher(事件监听器):是ZK的一个很重要的特性。ZK允许用户在指定ZNode上面注册一些Watcher,当事件触发后,Server会将客户端感兴趣的事件通知给Client。
ACL
ZK采用ACL(Access Control Lists)策略来进行权限控制,类似于UNIX的权限控制。定义了如下5种权限:
CREATE:创建子节点的权限。
READ:获取节点数据和子节点列表的权限。
WRITE:更新节点数据的权限。
DELETE:删除子节点的权限。
ADMIN:设置节点ACL权限。
参考:《从Paxos到ZooKeeper》



