本篇主要阐述一下java垃圾收集的几种算法(垃圾收集主要发生在Java堆和方法区)。其中主要包括:引用计数法(JVM未使用)、标记-清除算法、标记-压缩(清理)算法、复制算法和分代收集算法。下面简单介绍一下其实现的原理。
引用计数法
引用计数法的实现相对简单,每个对象的实例都保存着被引用的个数。该数值随着被引用的个数的增减而增减。但是由于引用计数法在引用成环的时候无法进行计数,故JVM并未采用该方法。如下图所示:
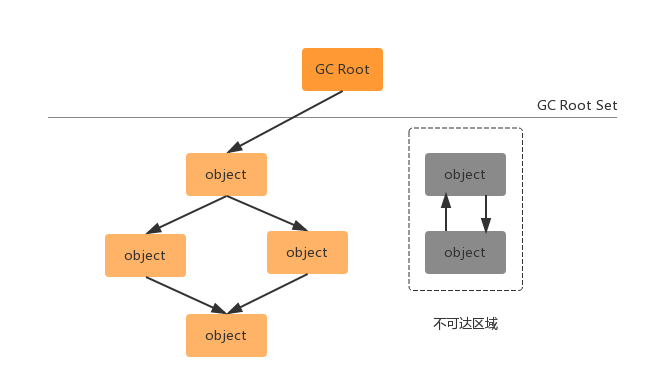
标记-清除算法
标记清除算法可以分为两个阶段:标记阶段和清除阶段。其中标记阶段标识出了所有需要回收的对象。其次在标记完成之后,对已经标记的对象实施清理工作。一个方面,原先已经被占用的内存空间的位置没有改变,这样以来就会产生大量的内存碎片;另外,标记清除的效率不高(当无效内存较多时,标记和清除都比较耗时)。如下图所示:
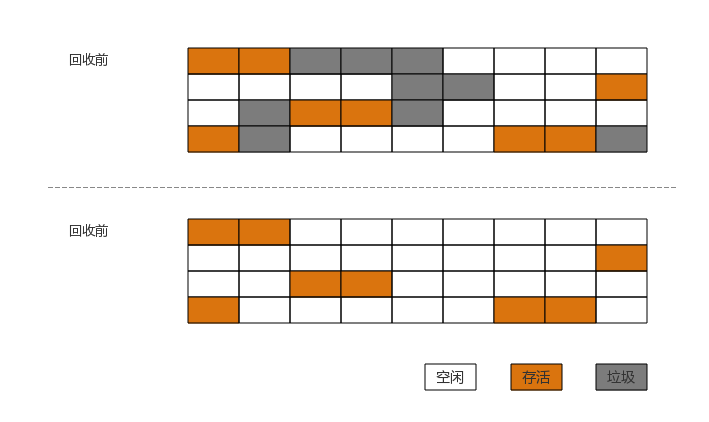
标记-压缩(清理)算法
标记-压缩算法相对于标记-清除算法而言,前半部分的过程相同,也就是标记阶段。但对于压缩阶段,它将有效的空间依次整理成连续的内存空间。完成之后,以最后的有效空间为边界,释放后面的所有内存空间。如下图所示:

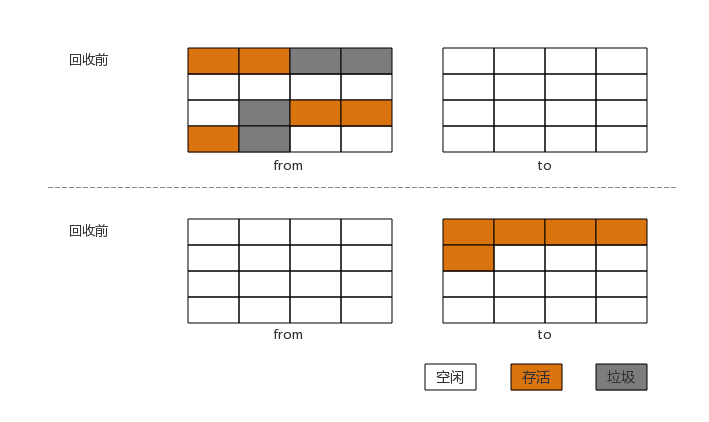
复制算法
复制算法概括为,内存中同时有两片相同大小的空间。同一时间只有一片空间可以被利用,另外一片空间则作为GC时,有效内存要拷贝到的空间。当数据从前一片空间中全部拷贝到后一片空间时,前一片的内存空间会被全部释放。如下图所示:
复制算法相对于其他几种算法而言,会浪费一半的内存空间。因此在实际的应用当中(以Hotspot为例),会使用复制算法结合标记-压缩(清理)的思想。其效果图如下所示:
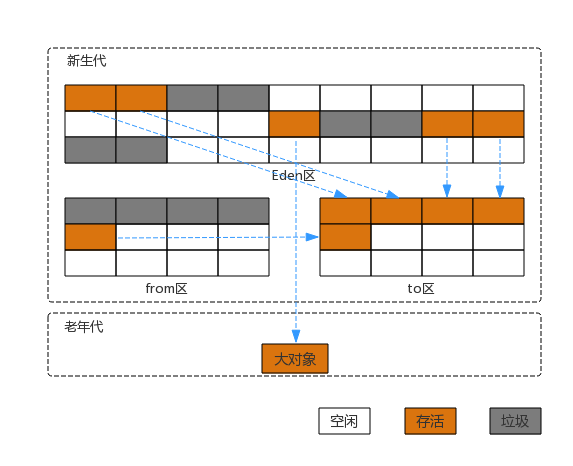
分代收集算法
当前商用的JVM大都使用了分代收集的思想,(以Hotspot为例)通常可以将堆内存分为新生代和老年代。新生代又可以分为,一块较大空间的Eden区和两块较小且相等的Survivor1和Survivor2区。每次新产生的对象优先放在Eden区,S1和S2区则存放年龄更大的对象,并且两者的GC算法为复制算法。年龄更大的对象则会进入老年代。其示意图可参考上面的“复制算法的整合示意图”。
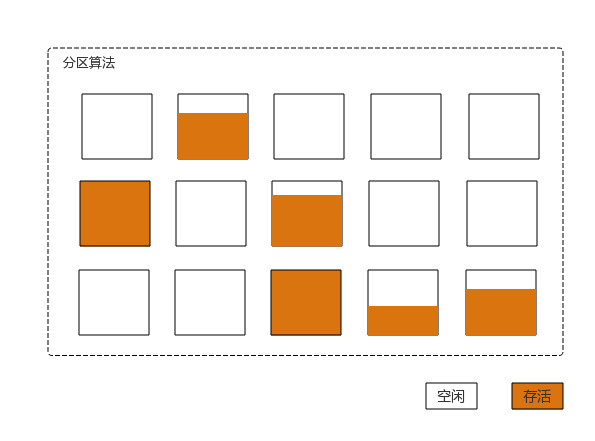
分区算法
分代算法按照对象的生命周期长短划分为2个部分,分区算法将整个堆空间划分为连续的不同小区间。每个小区间独立使用,独立回收。如下图所示:(对于具体的描述,参见后续的G1收集器介绍)
参考:《实战Java虚拟机》



