在多线程的开发当中,如果我们大量的使用new Thread()的方式去创建线程的话,则会使系统内存被过度消耗(JDK1.5以后,创建一个线程的开销是1M),从而使系统崩溃。
除此之外,线程创建和销毁的过程中也是很消耗资源的。很有可能出现,线程本身创建和销毁的开销比业务的开销还要大。因此,线程池是一个不二的选择,并且JUC提供了一套完善的线程池的类库,下面介绍一下。
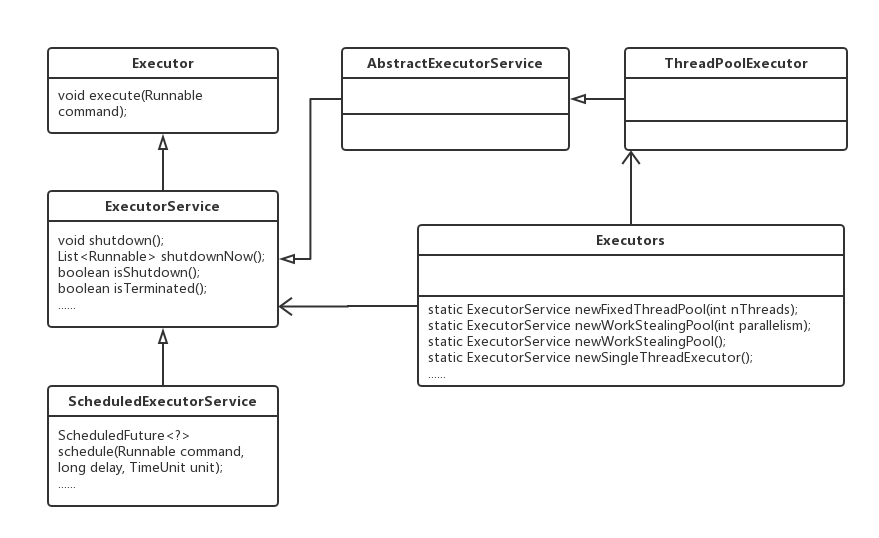
Executors里面提供了许多静态方法,用于构造常用的线程池。其常用API如下:
// 该方法会创建一个固定数量的线程池,如果提交的数量多于n,则多于的线程进入等待队列LinkedBlockingQueue(该队列可以无限大,直到内存上限)
static ExecutorService newFixedThreadPool(int nThreads);
// 该方法会创建线程数为1的线程池,如果提交的数量多于1,则多于的线程进入等待队列LinkedBlockingQueue(该队列可以无限大,直到内存上限)
static ExecutorService newSingleThreadExecutor();
// 创建一个最大数量为Integer.MAX_VALUE的线程池,线程空闲最大存活时间是60S
static ExecutorService newCachedThreadPool();
// 创建大小为1的线程池,不过可以提供某一个延时时候的执行任务
static ScheduledExecutorService newSingleThreadScheduledExecutor();
// 与上面的方法类似,不过可以自定义线程数量
static ScheduledExecutorService newScheduledThreadPool(int corePoolSize);
下面简单介绍一下几类线程池的用法:
固定大小的线程池
public class ThreadPoolDemo {
public static class MyTask implements Runnable {
@Override
public void run() {
System.out.println(System.currentTimeMillis() + ": Thread Id:" + Thread.currentThread().getId());
try {
Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
MyTask task = new MyTask();
ExecutorService es = Executors.newFixedThreadPool(5);
// ExecutorService es = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
es.submit(task);
}
}
}如上述代码所示,newFixedThreadPool(5) 创建出来的线程池,线程是5作为一个批次执行的,如果换成newCachedThreadPool()则是10个一起执行完成的。
计划任务线程池
当我们使用newScheduledThreadPool(int corePoolSize)创建线程池时,返回的就是一个ScheduledExecutorService类型的对象。其包含的方法大致如下:
// 在给定延迟后,执行线程
public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit);
// 在给定延迟后,执行线程
public <V> ScheduledFuture<V> schedule(Callable<V> callable, long delay, TimeUnit unit);
// 以指定速度执行线程,如果线程执行时间t > delay则是t,否则是delay
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit);
// 以指定速度执行线程,当线程执行完成后,以delay的延迟,然后再执行下一个
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit);下面给出一个简单的事例
public class ScheduledExecutorServiceDemo {
public static void main(String[] args) {
ScheduledExecutorService ses = Executors.newScheduledThreadPool(10);
// // 如果前面的任务没有完成,则调度也不会启动
// ses.scheduleAtFixedRate(new Runnable() {
// @Override
// public void run() {
// try {
// Thread.sleep(4000);
// System.out.println(System.currentTimeMillis() / 1000);
// } catch (Exception e) {
// e.printStackTrace();
// }
// }
// }, 0, 2, TimeUnit.SECONDS);
// 前一个任务完成后,延迟2S执行
ses.scheduleWithFixedDelay(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(4000);
System.out.println(System.currentTimeMillis() / 1000);
} catch (Exception e) {
e.printStackTrace();
}
}
}, 0, 2, TimeUnit.SECONDS);
}
}线程池详解
Executors类提供了一些常用的创建线程池的静态方法,但是归根结底都是ThreadPoolExecutor和ScheduledThreadPoolExecutor的实例。下面给出几个静态方法:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}通过上面代码可以看出,这几类常用的线程池都是ThreadPoolExecutor类的实例对象。下面详细介绍一下该类,构造器声明如下:
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize,
long keepAliveTime, TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory, RejectedExecutionHandler handler);构造器参数详解如下:
corePoolSize:核心线程的数量;
maximumPoolSize:最大的线程数量;
keepAliveTime:当线程数量大于corePoolSize时,多余的线程的最大存活时间(如果空闲的话);
unit:keepAliveTime的单位;
workQueue:提交但尚未被执行的任务队列;
threadFactory:线程工厂,用于创建线程;
handler:拒绝策略,当任务提交不能被执行时的补救措施;
任务队列:workQueue
直接提交队列:SynchronousQueue提供了该功能,该队列没有容量,每一个任务的插入都需要等待一个任务删除操作。因此,如果使用了SynchronousQueue队列,通常都需要一个很大的maximumPoolSize,否则就很容易进入拒绝策略。
有界任务队列:可以使用ArrayBlockingQueue来实现,该阻塞队列有一个容量n。当提交线程到达corePoolSize时,开始往队列中压入。
无界任务队列:可以通过LinkedBlockingQueue实现,该阻塞队列的容量可以无限大,直到内存耗尽为止。
优先任务队列:可以通过PriorityBlockingQueue实现。对于任务执行的先后顺序ArrayBlockingQueue和LinkedBlockingQueue都是先进先出的原则。而对于PriorityBlockingQueue则是可以自定义优先级,从而更加灵活的控制线程的执行顺序。
对于ThreadPoolExecutor的执行顺序,有以下总结:
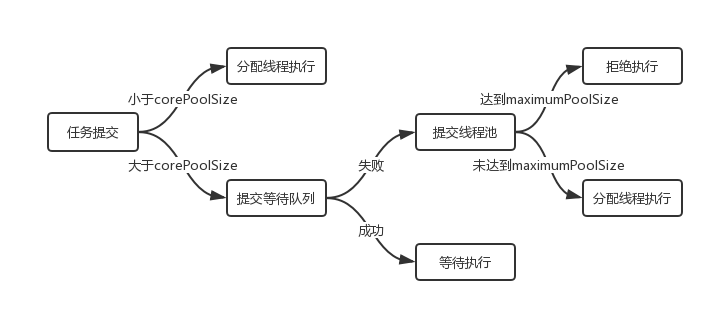
拒绝策略:handler
拒绝策略是当系统超负荷运转的时候,有可能出现的情况。JDK本身提供了4种内置的拒绝策略:AbortPolicy、CallerRunsPolicy、DiscardOldestPolicy和DiscardPolicy。下面介绍一下这集中策略:
AbortPolicy:会直接抛出异常,影响系统正常工作;
CallerRunsPolicy:只要当前线程池未关闭,就直接在当前线程中运行任务的run()。(并不是start());
DiscardOldestPolicy:从当前队列中获取一个最老的,未执行的任务丢弃,之后再尝试提交任务;
DiscardPolicy:直接丢弃这个任务;
除了上面的四种拒绝策略,还可以实现RejectedExecutionHandler接口,实现自定义的拒绝策略。下面给出一个demo:
public class RejectThreadPoolDemo {
public static class MyTask implements Runnable {
@Override
public void run() {
System.out.println(System.currentTimeMillis() + ": Thread ID:" + Thread.currentThread().getId());
try {
Thread.sleep(100);
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws InterruptedException {
MyTask task = new MyTask();
ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.SECONDS, new LinkedBlockingQueue<>(10),
Executors.defaultThreadFactory(), new RejectedExecutionHandler() {
// 自定义拒绝策略
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println(r.toString() + " is discard");
}
});
for (int i = 0; i < Integer.MAX_VALUE; i++) {
es.submit(task);
Thread.sleep(10);
}
}
}线程工厂:threadFactory
在我们使用线程池的过程中,如果我们需要在日志中打出可以方便让人理解的线程信息,那么重写ThreadFactory是一个不二的选择。下面附送一个demo:
public class CommonThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
/** 模块名 */
private String moduleName;
/** 功能名 */
private String functionName;
public CommonThreadFactory(String moduleName, String functionName) {
this.moduleName = moduleName == null ? "" : moduleName;
this.functionName = functionName == null ? "" : functionName;
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() : Thread.currentThread().getThreadGroup();
// 在线程名上加上模块名标示,方便调试
namePrefix = this.moduleName + "-" + this.functionName + "-pool-" + poolNumber.getAndIncrement() + "-thread-";
}
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r, namePrefix + threadNumber.getAndIncrement(), 0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}自定义ThreadPoolExecutor
对于ThreadPoolExecutor本身,我们也可以自定义其行为。可以重写下面的方法,来实现处理线程执行前后的一些逻辑。
protected void beforeExecute(Thread t, Runnable r);
protected void afterExecute(Runnable r, Throwable t);
protected void terminated();下面附加一个demo:
public class ExtThreadPool {
public static class MyTask implements Runnable {
public String name;
public MyTask(String name) {
this.name = name;
}
@Override
public void run() {
System.out.println("正在执行:Thread ID: " + Thread.currentThread().getId() + " Task name= " + name);
try {
Thread.sleep(100);
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws InterruptedException {
ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>()) {
@Override
protected void beforeExecute(Thread t, Runnable r) {
System.out.println("准备执行:" + ((MyTask) r).name);
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
System.out.println("执行完成:" + ((MyTask) r).name);
}
@Override
protected void terminated() {
System.out.println("线程池退出");
}
};
for (int i = 0; i < 5; i++) {
MyTask task = new MyTask("TASK-GEYM-" + i);
es.execute(task);
Thread.sleep(10);
}
es.shutdown();
}
}线程池大小
下面提供了一个计算公式:最佳线程数目 = ((线程等待时间+线程CPU时间)/线程CPU时间 )* CPU数目
还有一点需要注意的就是,在提交的Task里面的run()方法的最外层,一定要抓住所有的异常,否则线程内部抛出来的异常会被吞噬掉!



